一、内置浏览器
1、基本概念
内置浏览器是八爪鱼采集器的默认采集模式,它的特点在于: (1)客户端内置:由客户端启动采集,模拟访问常规浏览器。 (2)后台静默运行:任务可以在后台持续执行。 (3)资源占用低:不需要启动完整浏览器、可以同时运行多个采集任务、对电脑性能要求更低。 (4)故障排查方便:内置浏览器窗口可显示网页内容、同时查看日志,快速定位问题。2、适用场景
大批量公开数据采集。 反爬较弱的常规页面。 资源有限,需同时运行多任务。3、 使用介绍
步骤一:确认采集规则任务
请先自定义配置完任务或者配置完模板任务。特别说明: a. 配置模板任务 b.内置浏览器模式是默认采集方式。
步骤二:启动采集
特别说明: a. 模板点击启动:
步骤三:查看采集状态
1.客户端会开两个窗口:一个源窗口,一个采集窗口。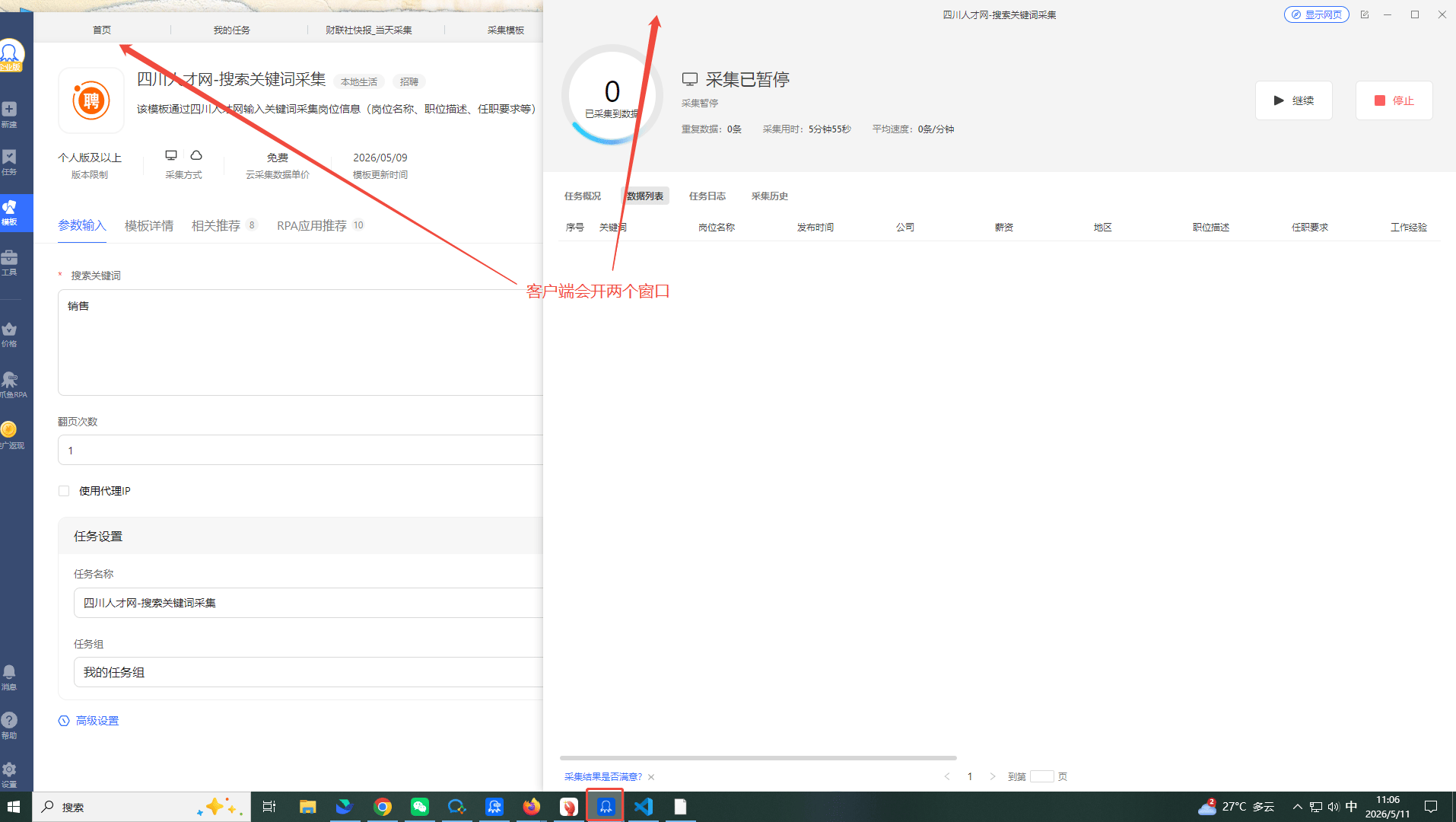
 任务概况:可查看采集开始/结束时间,去重后数量以及资源使用情况(验证码、代理IP)。
数据列表:可以预览采集到的数据。
任务概况:可查看采集开始/结束时间,去重后数量以及资源使用情况(验证码、代理IP)。
数据列表:可以预览采集到的数据。
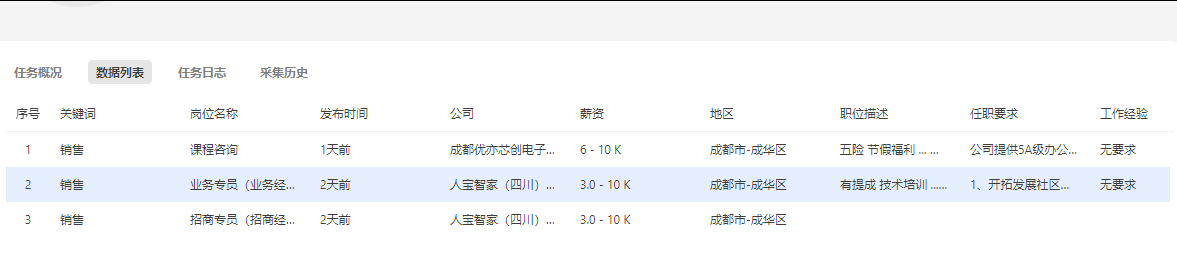
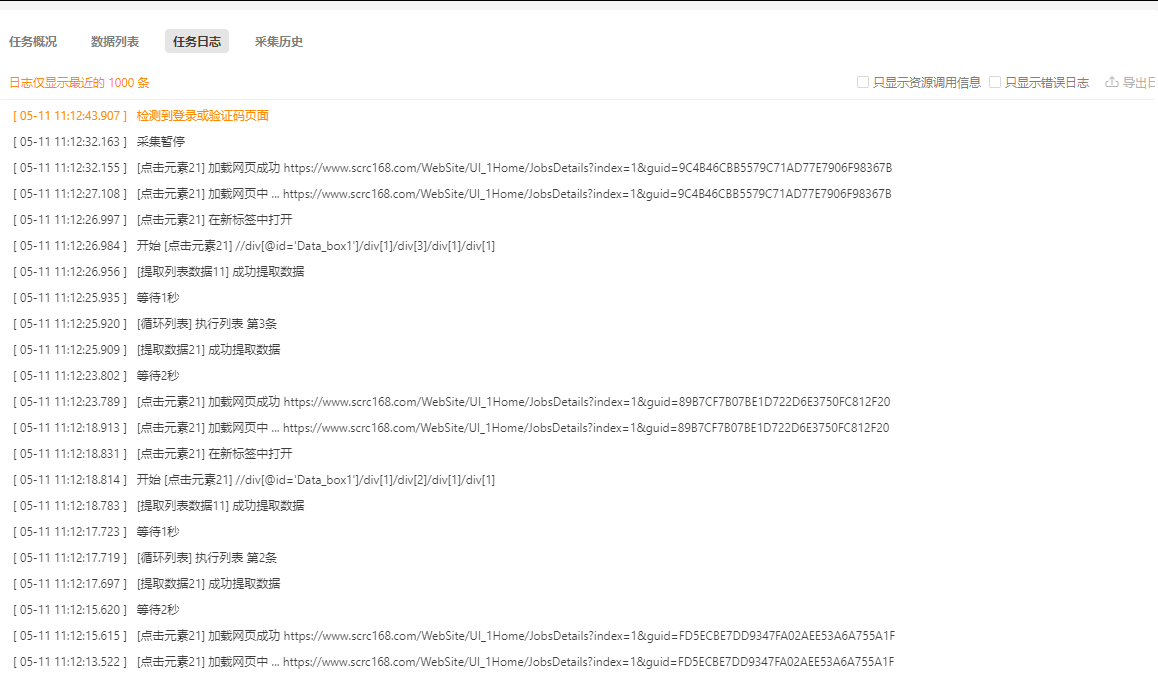

特别说明: a. 打开显示网页结合日志是排查问题的关键步骤。具体请参考:本地排错4.采集运行控制 暂停:可以停止流程采集,用于控制/操作流程间突发验证与排错。 停止:直接终止采集。

步骤四:数据导出
点击停止或者正常采集结束,选择导出方式即可。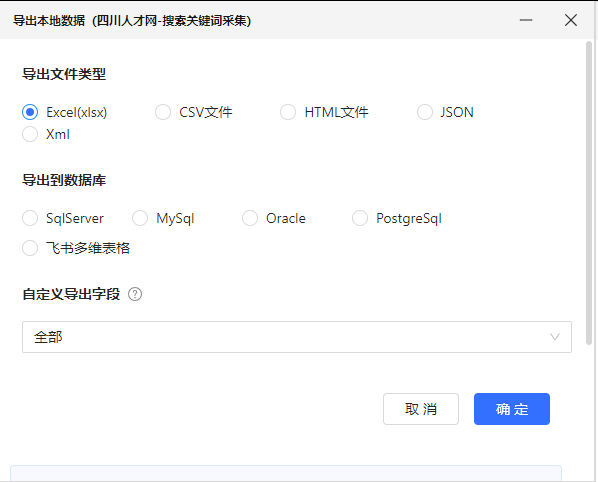
二、独立浏览器
1、基本概念
独立浏览器是八爪鱼采集器针对高难度反爬场景推出的解决方案。它的核心优势在于: (1)真实浏览器环境:网站难以区分是真人还是爬虫。 (2)全程可见可控:打开独立浏览器窗口,采集过程一览无余、发现异常可以随时手动干预、新弹出的窗口会单独显示。2、适用场景
目标网站需要账号登录。 反爬检测严格(频次、行为分析)。 需要人工确认或干预的流程。 采集过程需要实时监控。 无需配置复杂的登录规则。 适合需要会话保持的采集任务。 可以随时暂停任务手动输入验证码,处理完继续执行,无缝衔接。3、 使用介绍
步骤一:确认采集规则任务
请先自定义配置完任务或者配置完模板任务。(请参考一、内置浏览器的该步骤)步骤二:启动采集
特别说明: a. 由于本地采集默认采集方式内置浏览器,所以要在下拉框选择独立浏览器采集。
步骤三:查看采集状态
1.客户端会开两个窗口:一个源窗口,一个采集窗口。同时独立浏览器会开一个新窗口用于采集。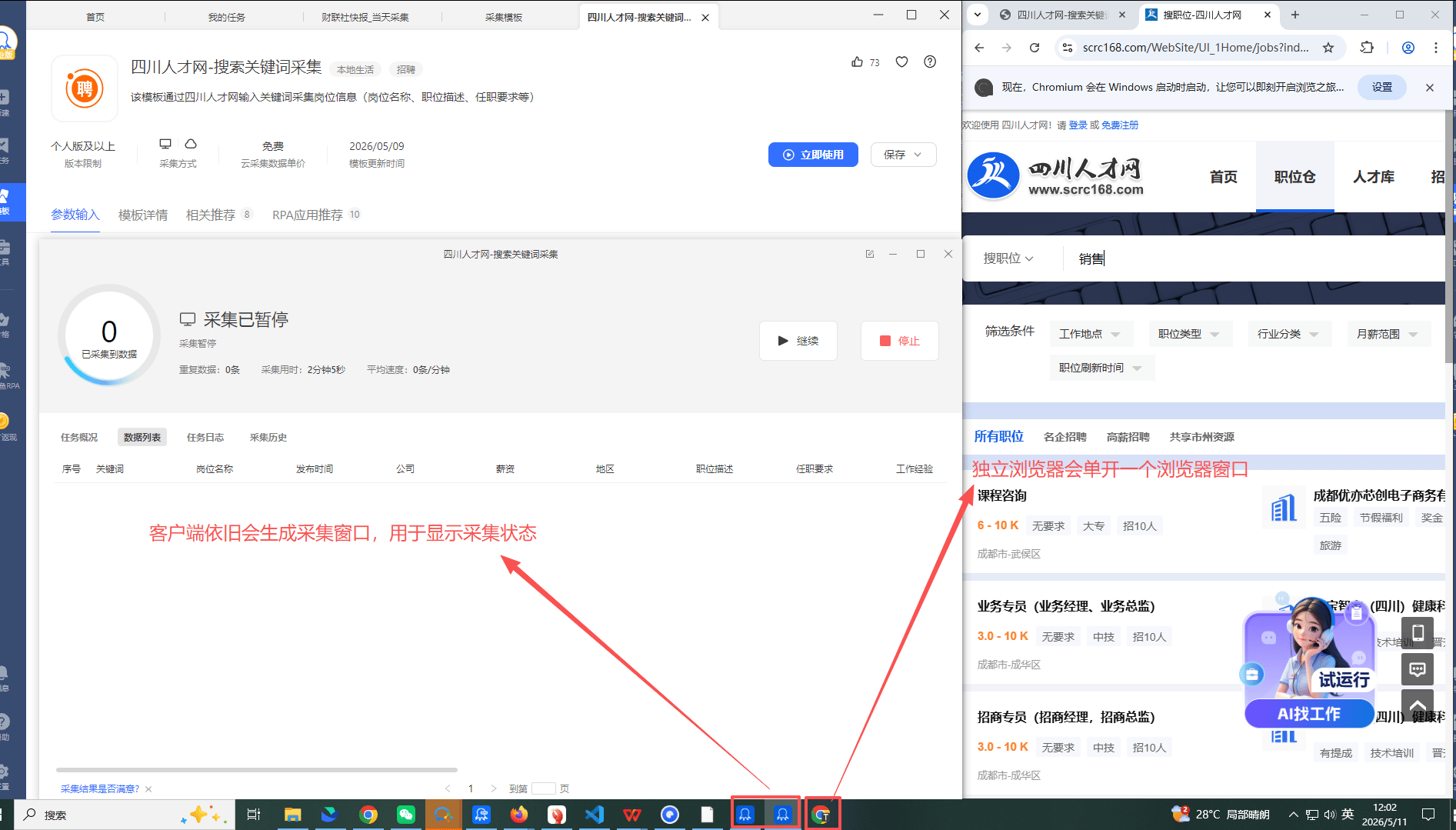
 任务概况:可查看采集开始/结束时间,去重后数量以及资源使用情况(验证码、代理IP)。
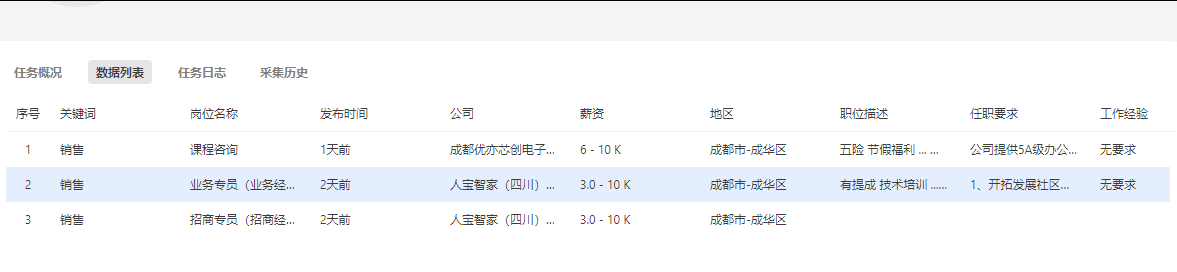
数据列表:可以预览采集到的数据。
任务概况:可查看采集开始/结束时间,去重后数量以及资源使用情况(验证码、代理IP)。
数据列表:可以预览采集到的数据。
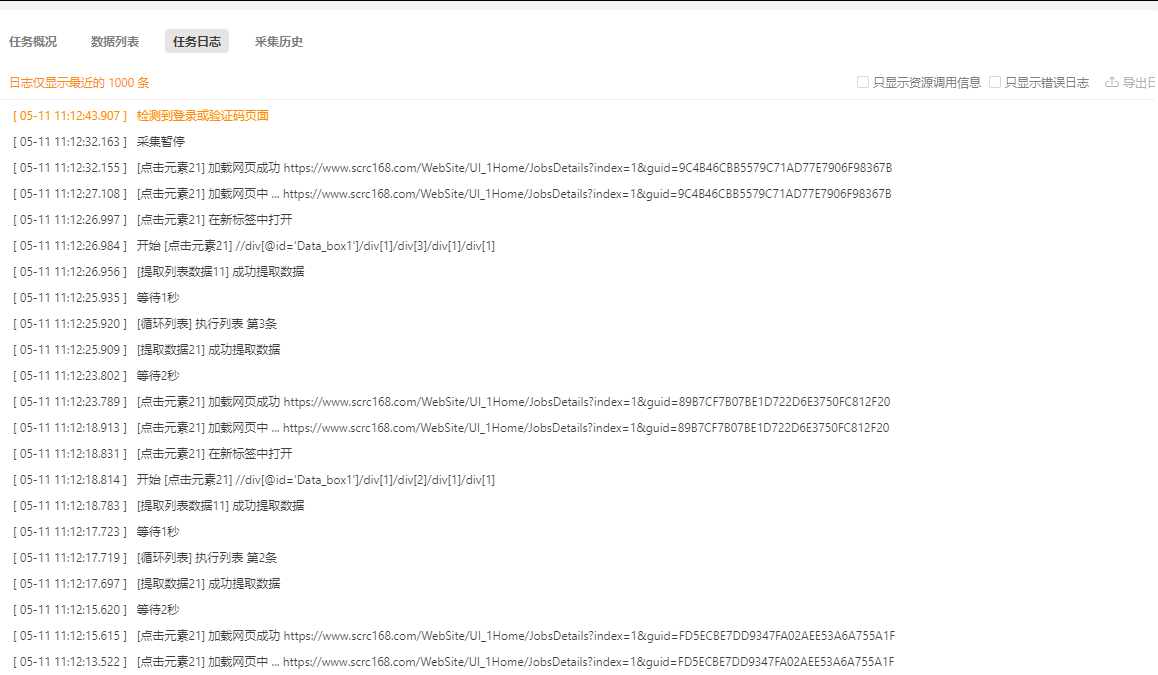

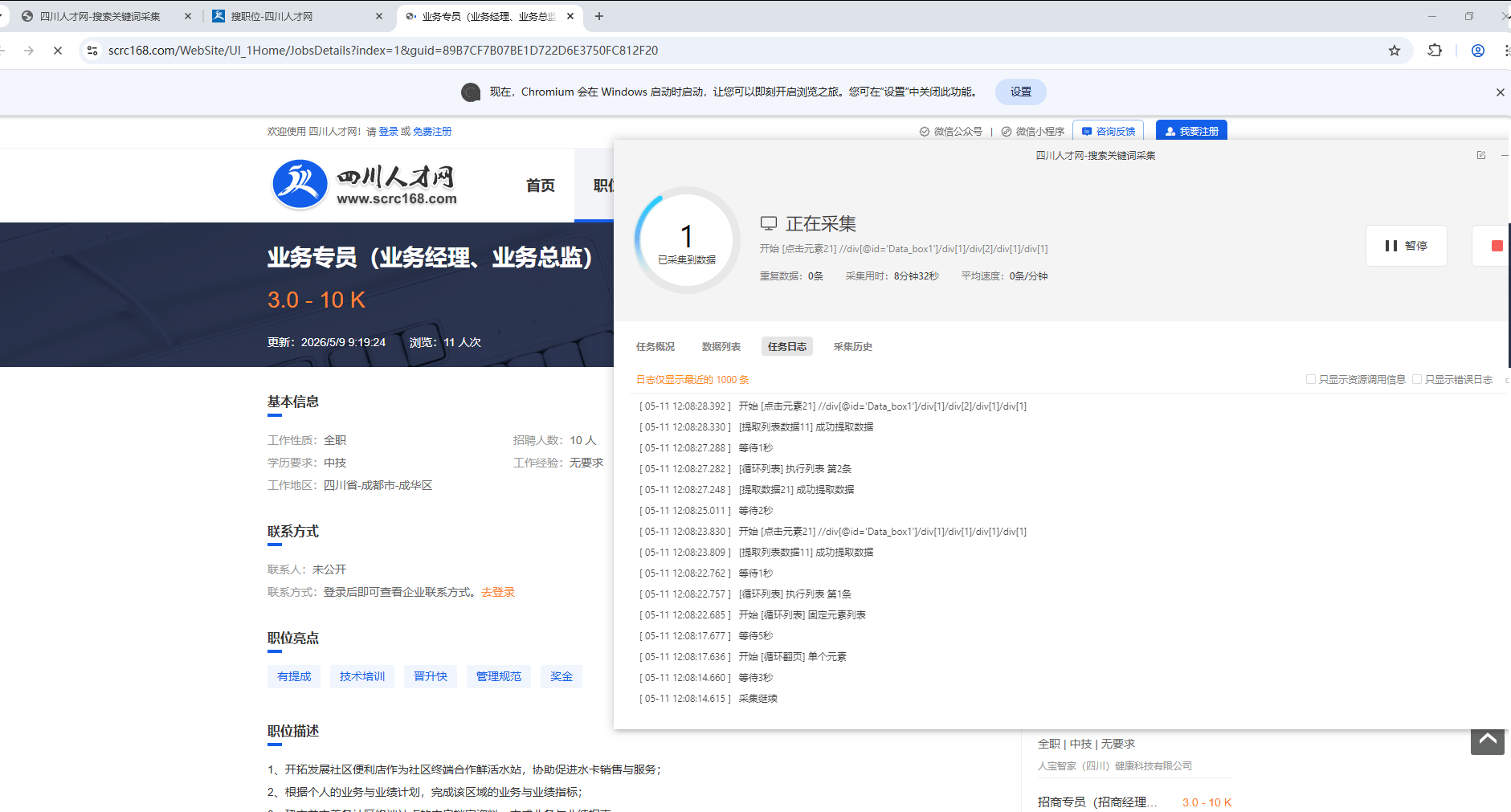
特别说明: a. 如果需要排错,建议用客户端日志窗口与新浏览器采集窗口对比排查。4.采集运行控制 暂停:可以停止流程采集,用于控制/操作流程间突发验证与排错。 停止:直接终止采集。

步骤四:数据导出
点击停止或者正常采集结束,选择导出方式即可。
三、模式对比与选择
1、模式对比
| 对比维度 | 内置浏览器 | 独立浏览器 |
|---|---|---|
| 技术原理 | 基于客户端内置浏览器执行 | 调用本地Chrome/Edge浏览器实时交互 |
| 反爬能力 | 较弱(易被识别为自动化工具) | 强(本地浏览器特征,真实用户行为) |
| 适用场景 | 公开数据、低反爬页面 | 需登录、有验证码、反爬强的网站 |
| 稳定性 | 高,任务可持续后台运行 | 关闭页面即终止任务 |
| 日志查看 | 网页与日志同步查看 | 任务窗口+独立浏览器窗口搭配使用 |
| 新开标签页 | 在内置窗口内打开 | 按独立窗口标准存在 |
2、场景推荐
| 场景 | 推荐方式 | 理由 |
|---|---|---|
| 电商商品详情(需登录) | 独立浏览器 | 保持登录态,处理验证码 |
| 社交媒体数据采集 | 独立浏览器 | 反爬强,需验证 |
| 新闻资讯批量采集 | 内置浏览器 | 低反爬,高效稳定 |
| 公开名录数据采集 | 内置浏览器 | 大批量,后台运行 |
| 企业信息工商数据 | 内置浏览器 | 反爬较弱,适合定时任务 |
| 行业网站内容监控 | 独立浏览器 | 反爬较强,需人工处理 |