一、手动执行规则
做好采集规则以后,我们最好手动执行一下规则,检查规则是否满足采集需求。 手动执行规则是什么意思?打开流程图界面,按照从上至下,由内而外的逻辑(点击查看流程执行逻辑教程),将每个步骤都点击一遍,并观察点击步骤后的页面情况。如果符合预期,没问题。如果不符合预期,则需要修改。1、手动执行规则,符合预期
特别说明: a. 在点击【循环列表】时,最好选择除第1项以外的项,防止循环只对第1个项有效。
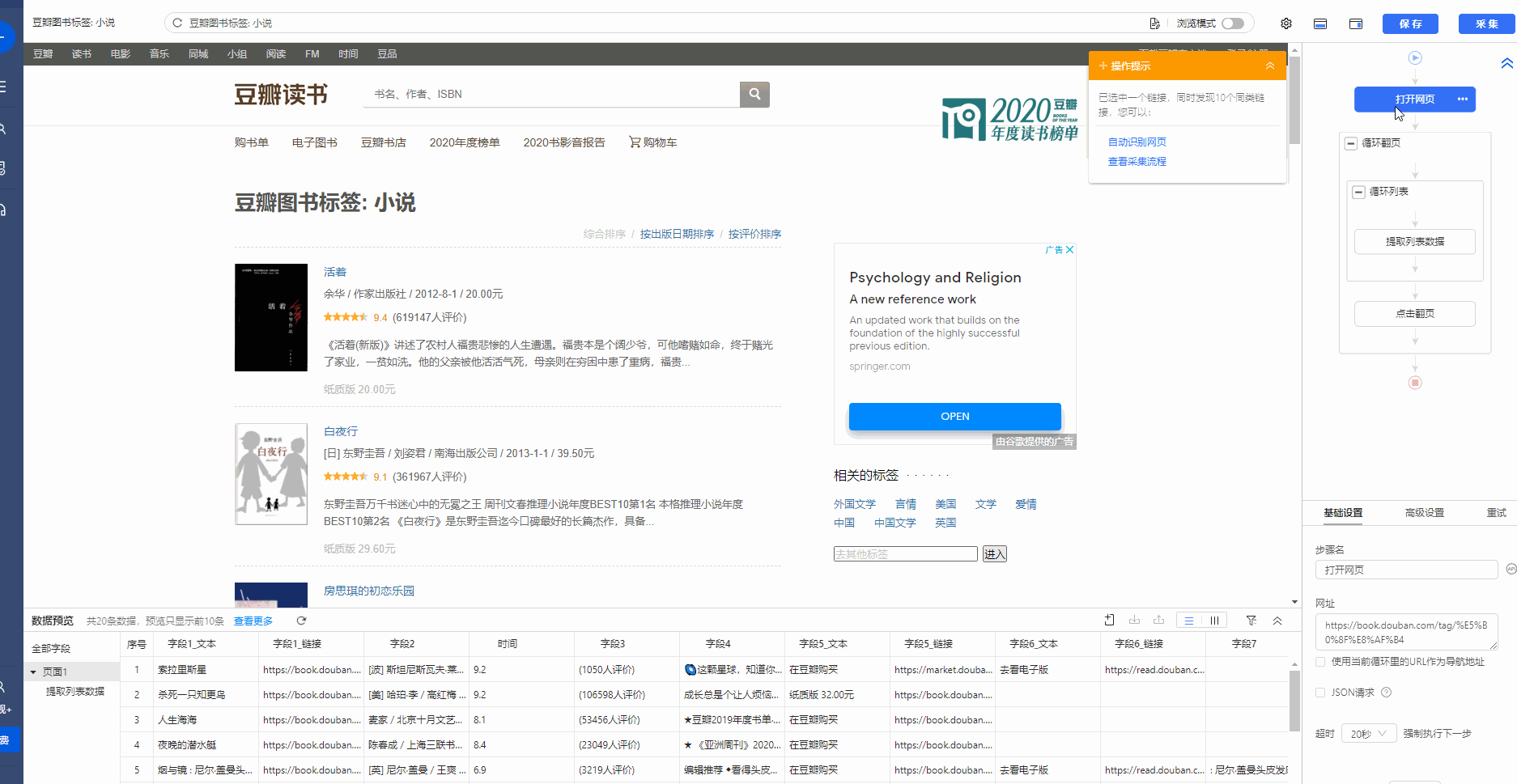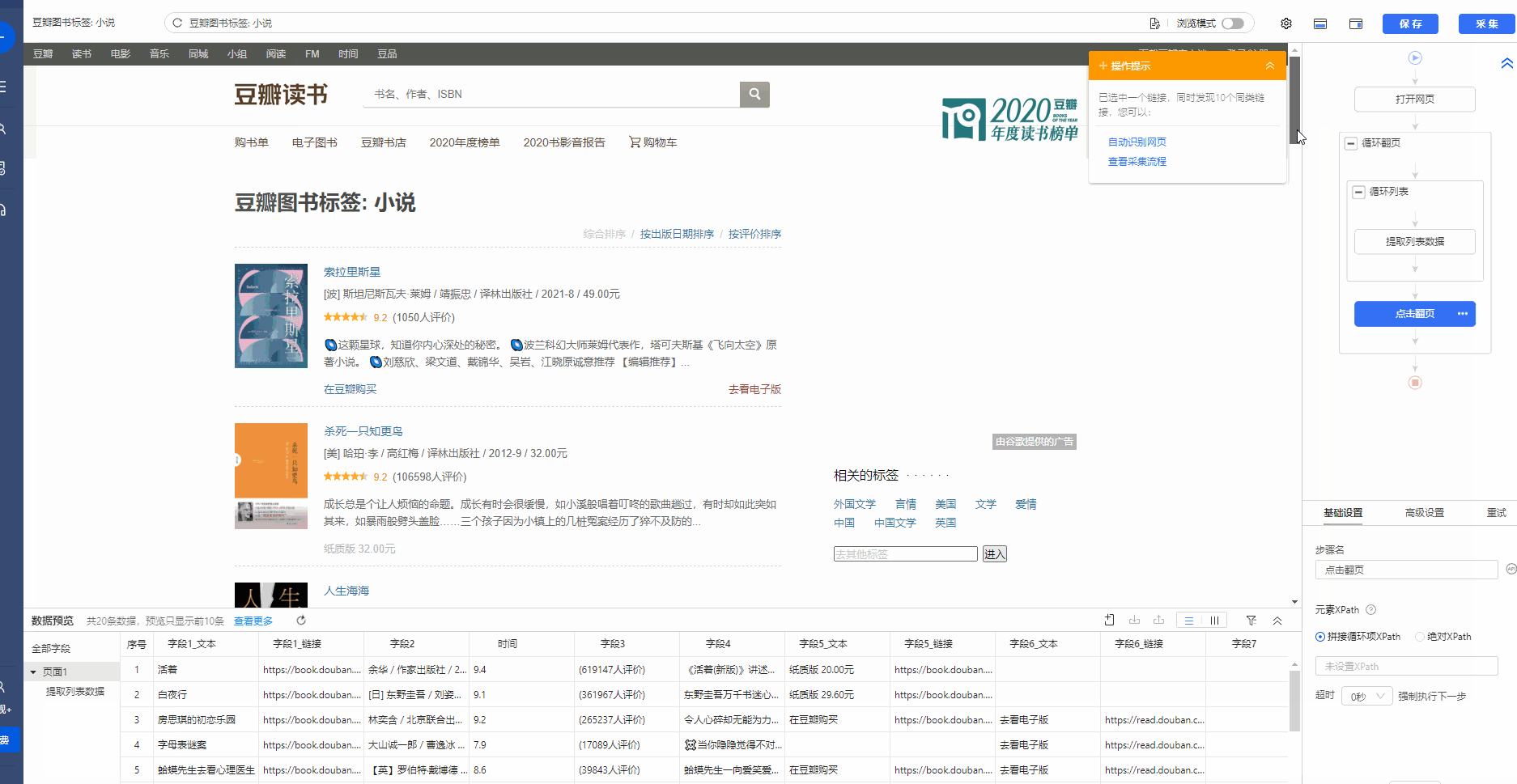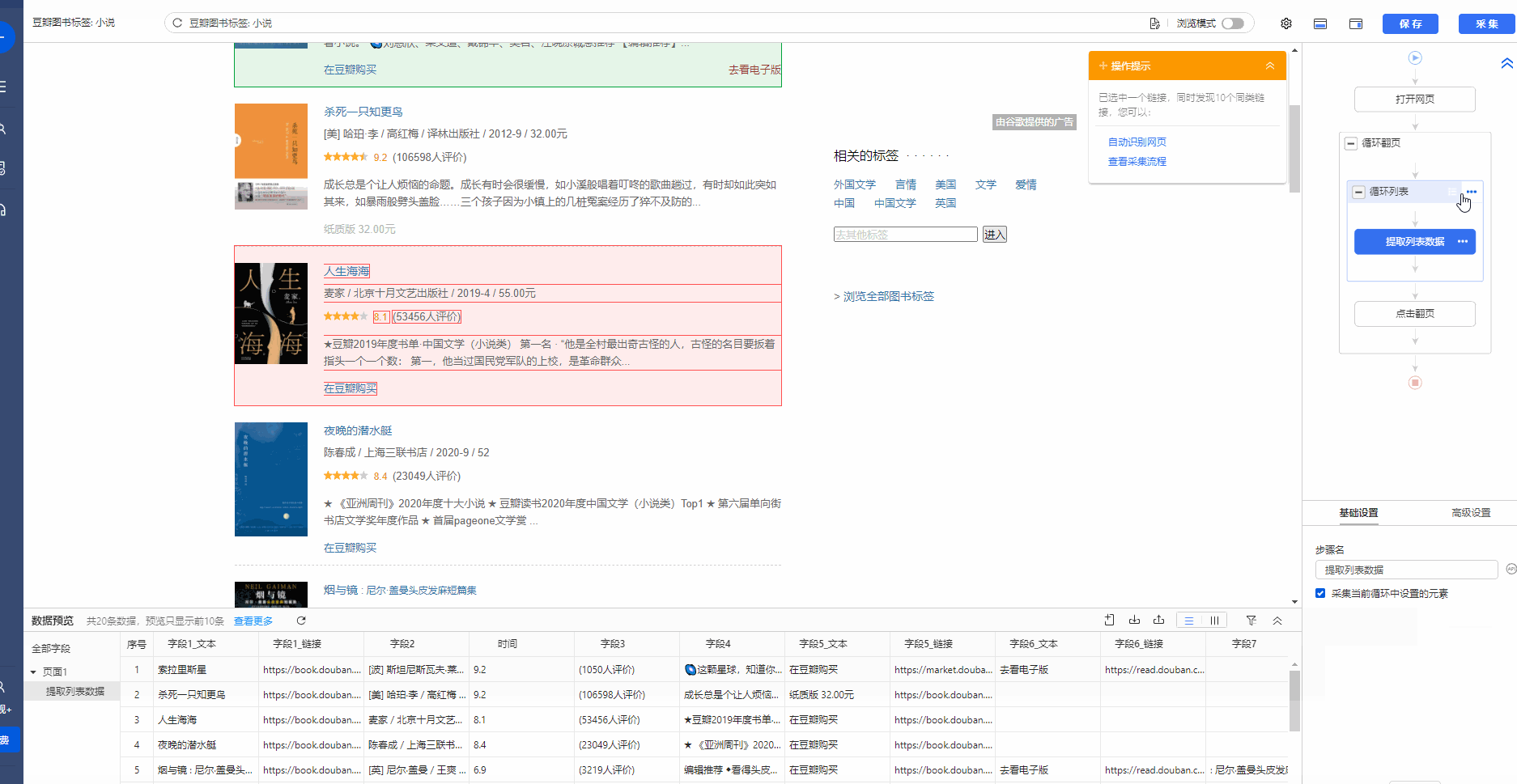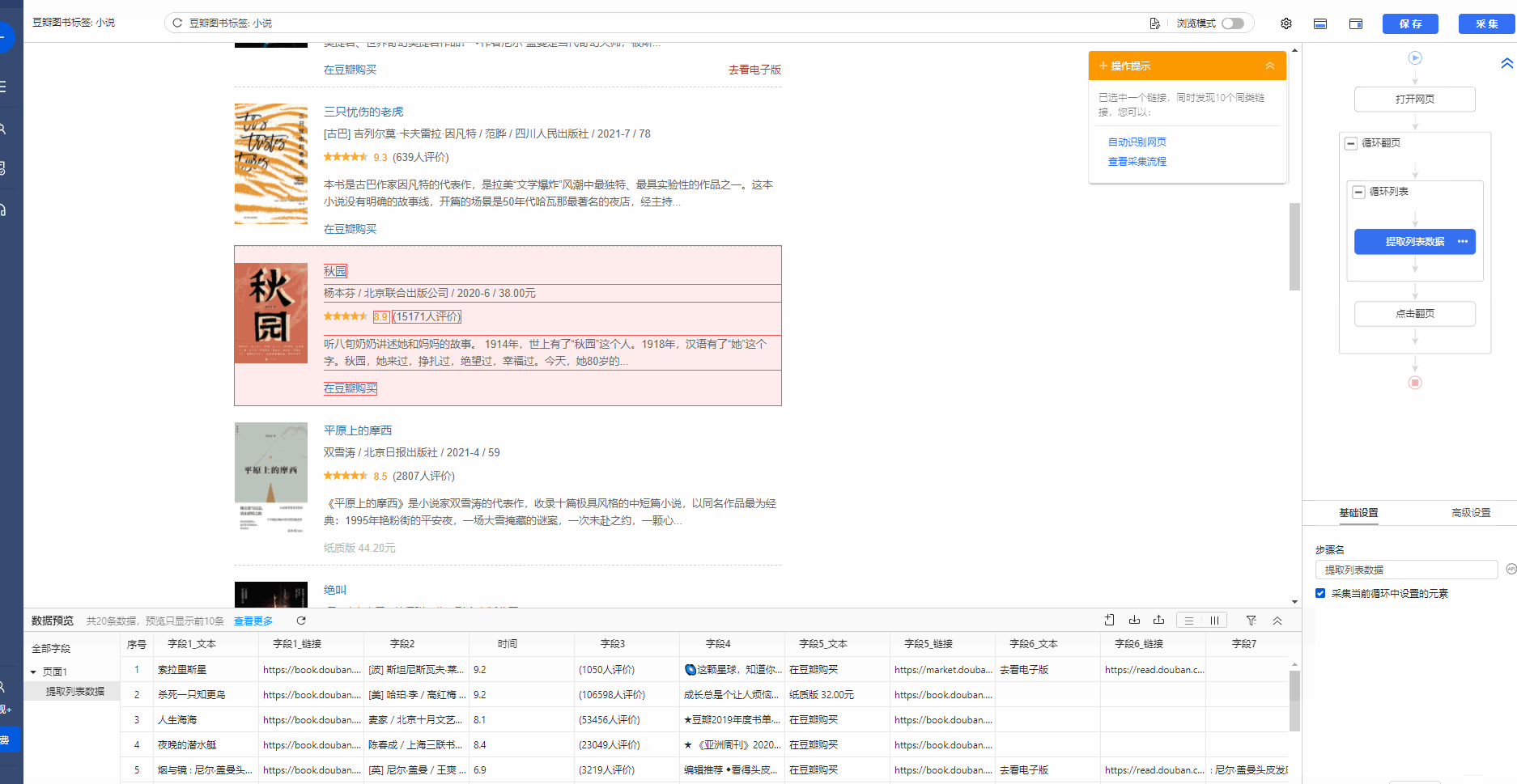
2、手动执行规则,不符合预期,可能有以下几种现象:
2.1、点击某个步骤后无响应
原因①:XPath定位不准,需修改定位XPath,点击查看 xpath获取方法。 原因②:多次修改此步骤导致底层代码错乱,需删掉此步骤重做一遍。2.2、提取到的数据不精准
表现为数据重复、数据错位、数据漏采等多种情况。提取数据不精准一般是在运行本地采集,拿到一些数据后更容易发现的。 因此,我们在下文 二、运行本地采集 中详细讲。二、运行本地采集
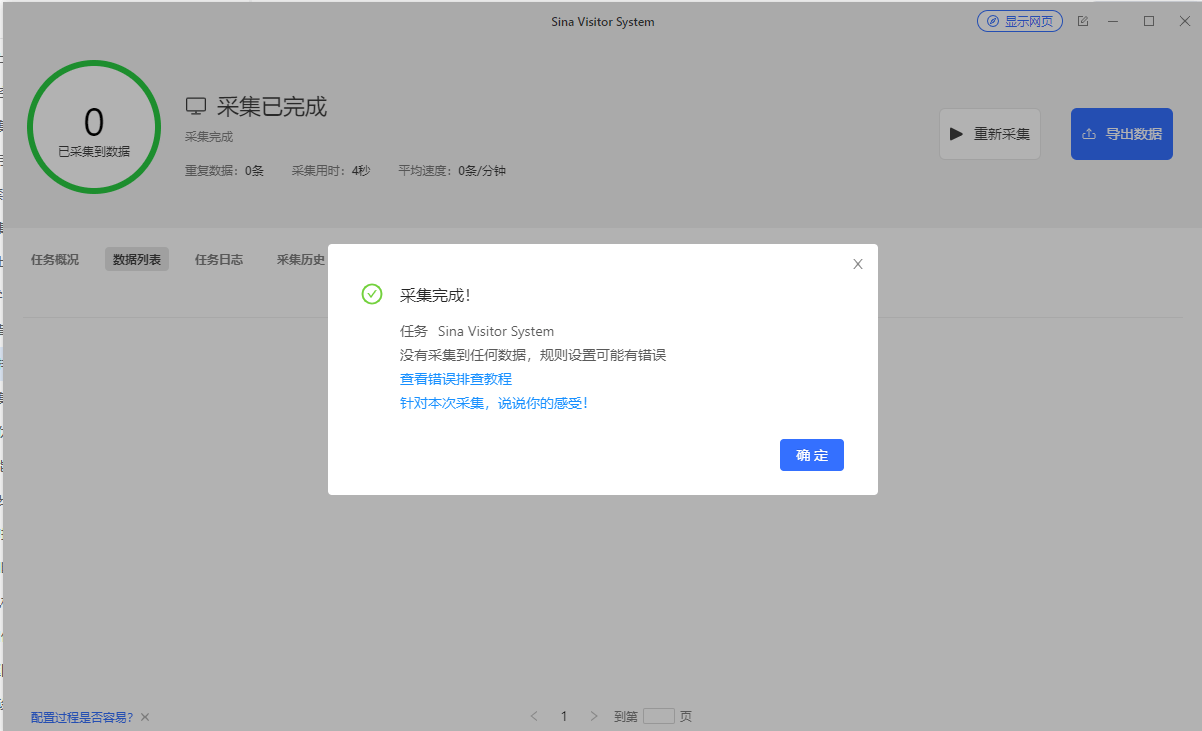
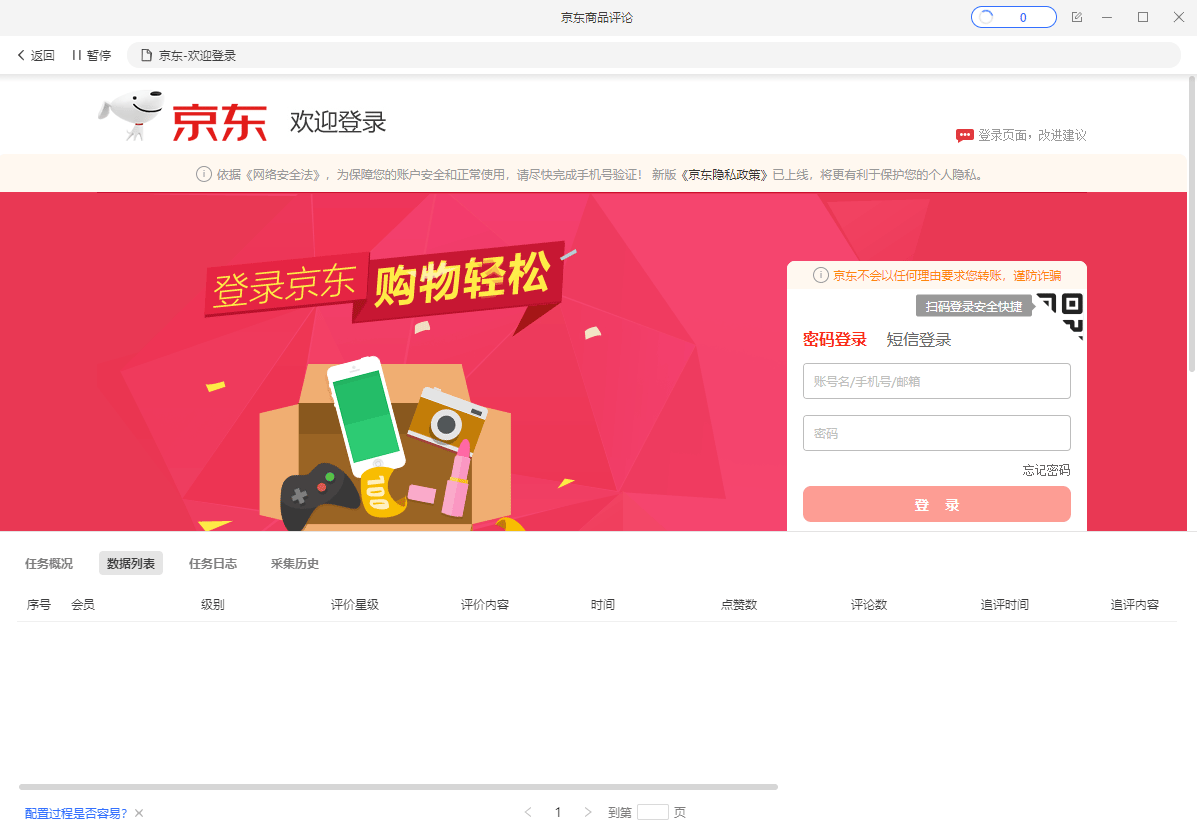
将任务启动本地采集。观察任务的采集状态,进而分析问题、解决问题。下面是一些常见的问题和解决方法汇总。1、采集数据为0
手动执行规则有数据,启动本地采集后,很快提示:【没有采集到任何数据】