一、【URL循环】操作演示
示例网址: https://movie.douban.com/subject/26387939/ https://movie.douban.com/subject/6311303/ https://movie.douban.com/subject/1578714/ https://movie.douban.com/subject/26718838/ https://movie.douban.com/subject/25937854/ https://movie.douban.com/subject/26743573/ https://movie.douban.com/subject/20451290/ https://movie.douban.com/subject/26816383/ 采集需求: 采集每个豆瓣电影详情页的电影Step1. 打开网页
在首页左上角点击【新建】—【自定义任务】。网址输入界面默认的是【手动输入】。将复制好的一批同类网址,粘贴进网址输入框中,并点击【保存网址】。八爪鱼中内置的浏览器会自动打开网页。同时,可以看到,流程中已自动创建【循环-打开网页】步骤。
特别说明: a. 手动输入的url数量不得大于1万个,如有超过1万url,请选择【从文件导入】,具体请查看教程 网址批量输入 b. Url还可以选择【从任务导入】和【批量生成】,具体请查看教程 网址批量输入
Step2. 按照需求配置所需的字段。
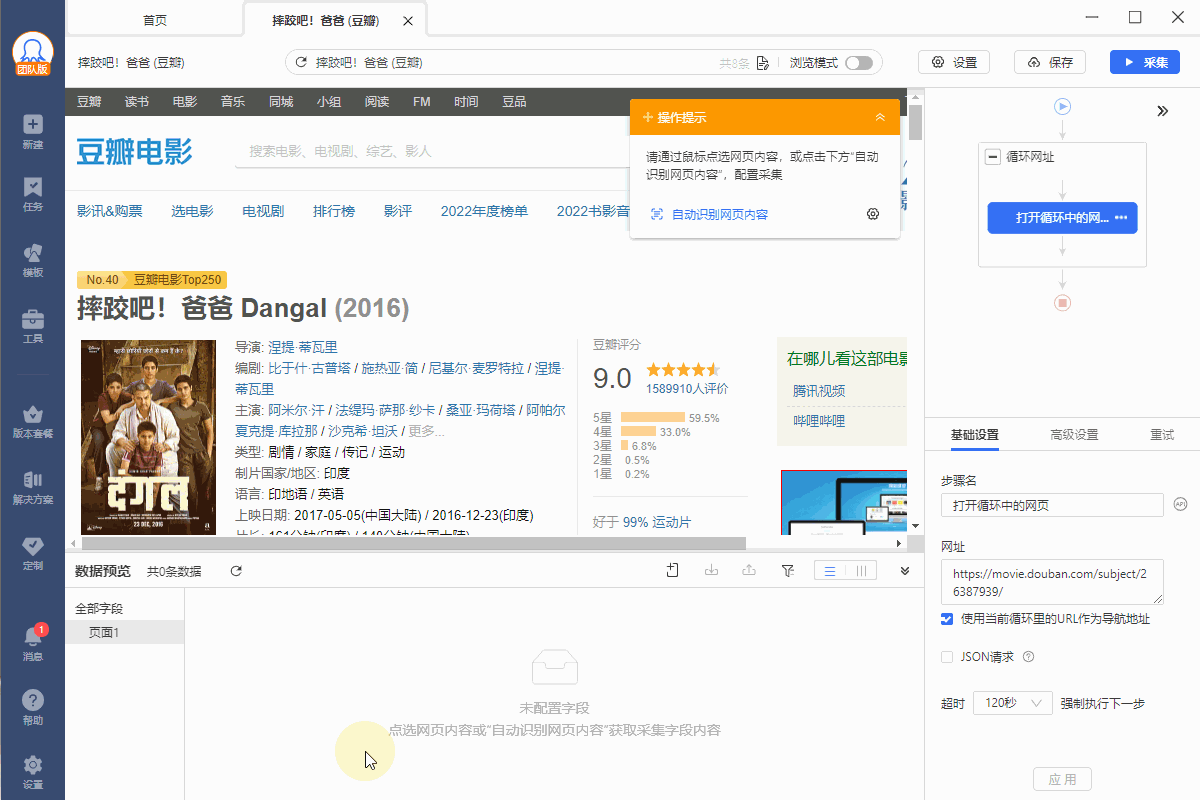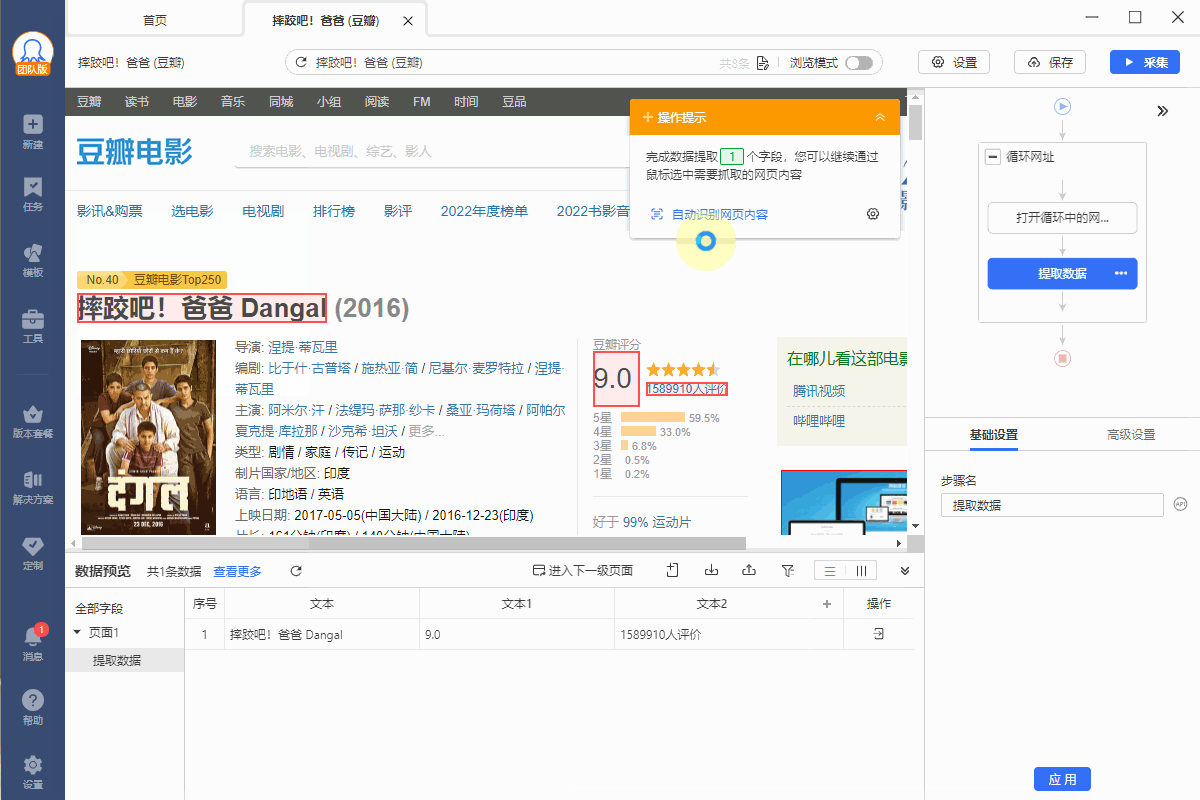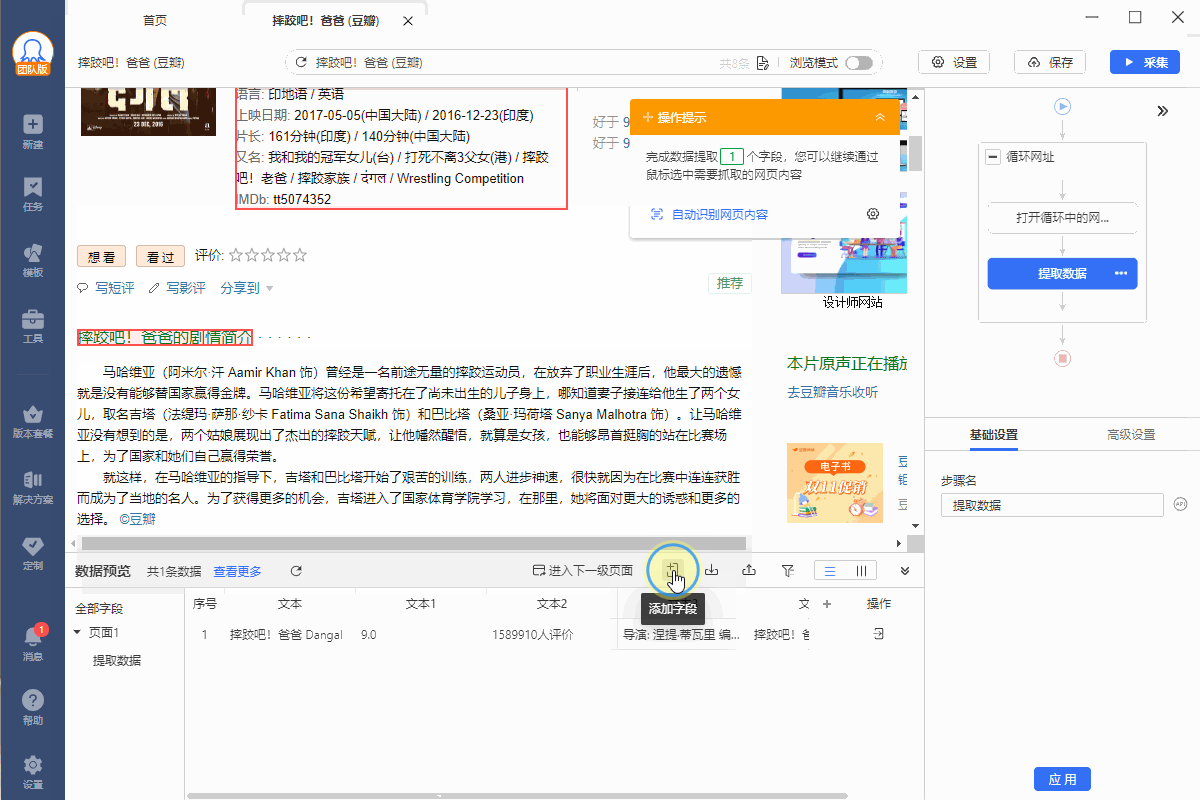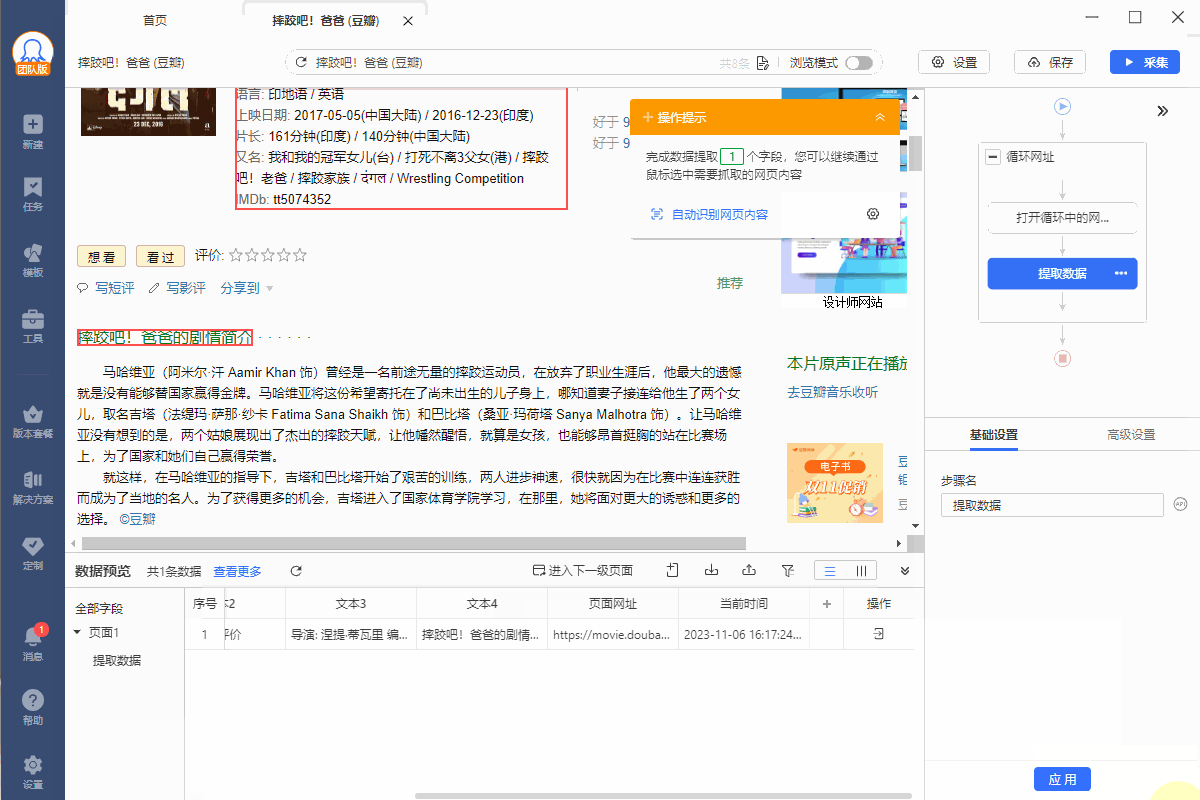
Step3. 配置完成后启动采集。
 采集到的数据示例如下图所示:
采集到的数据示例如下图所示:
