一、防采集
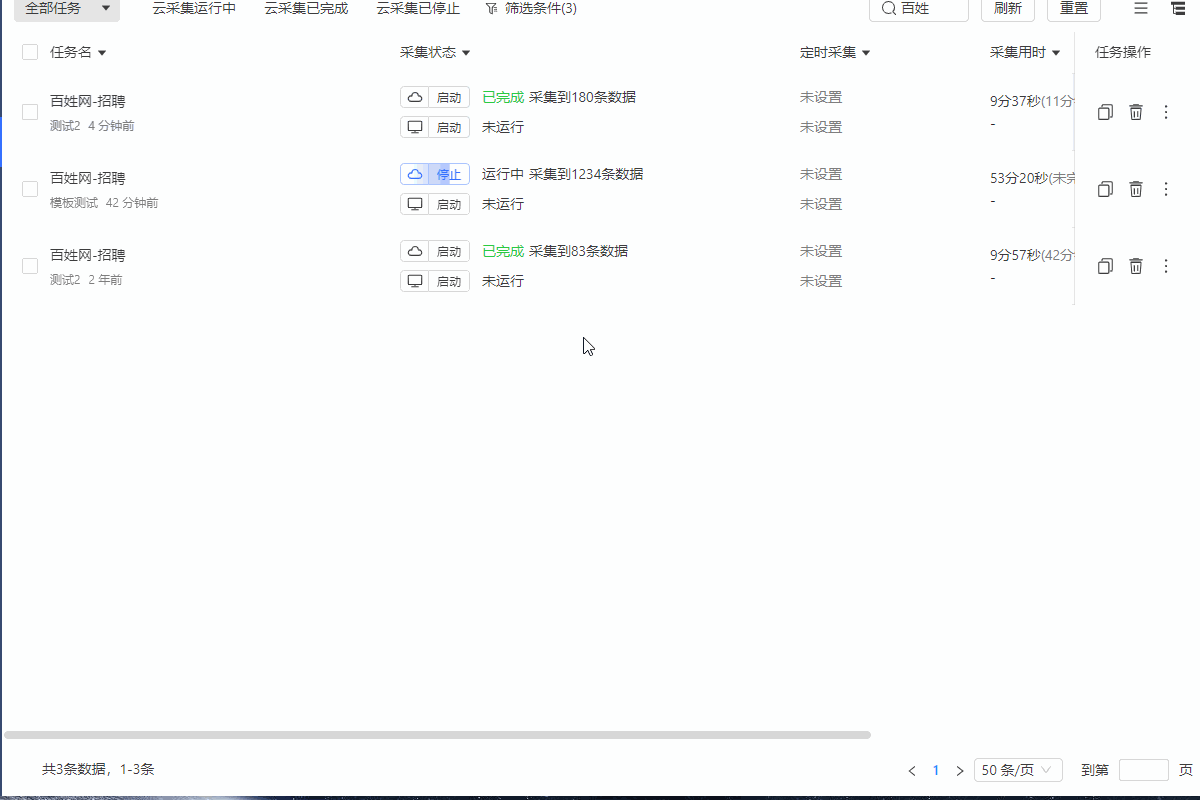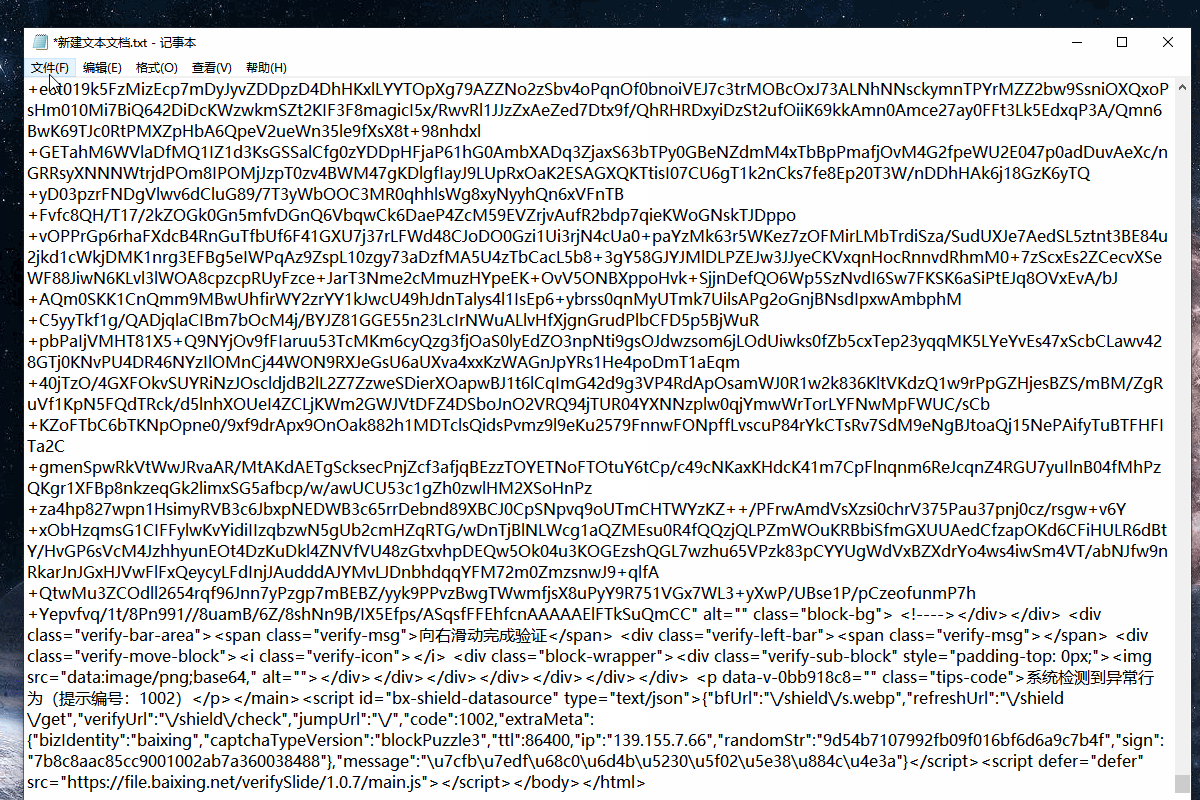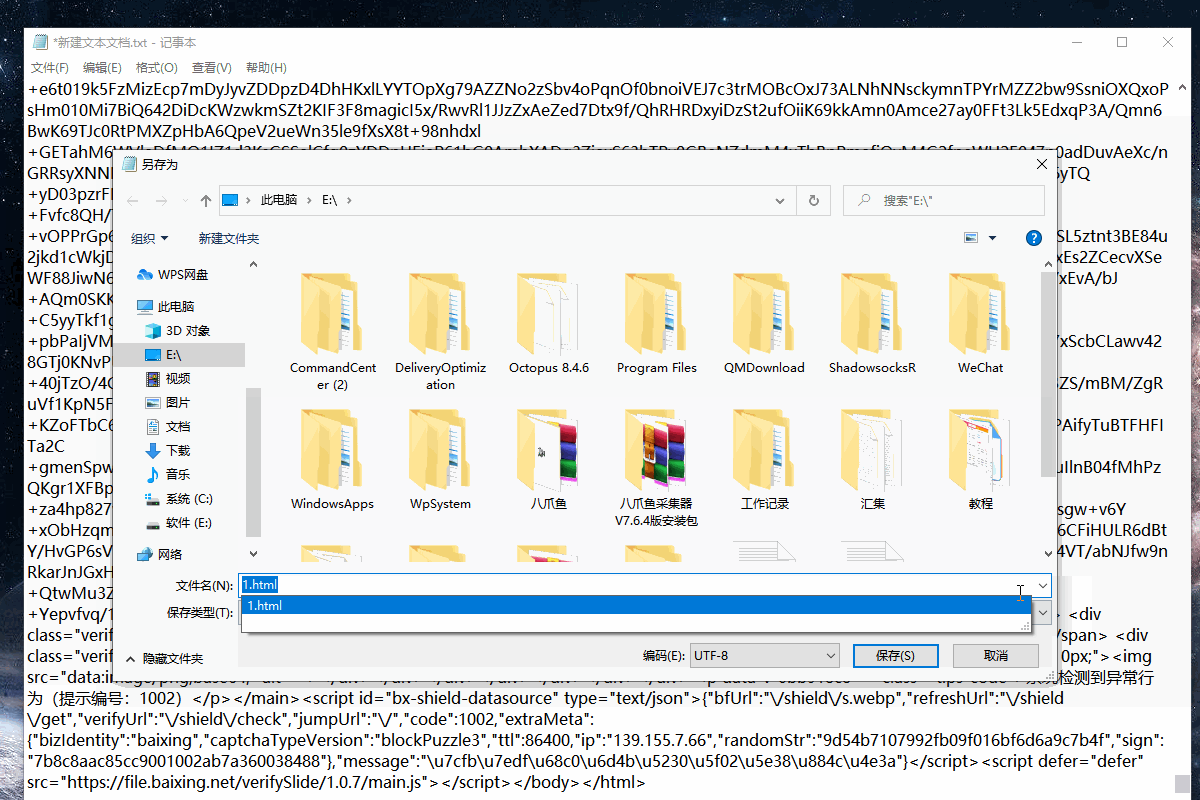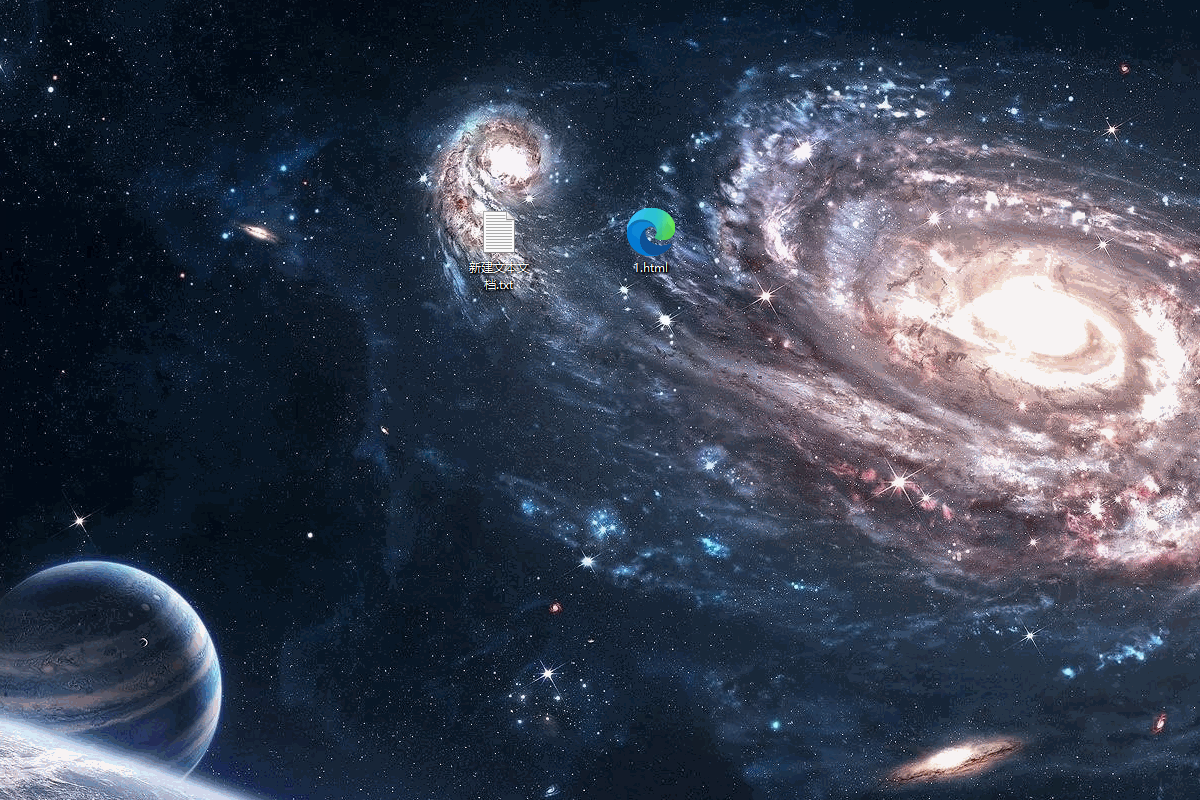
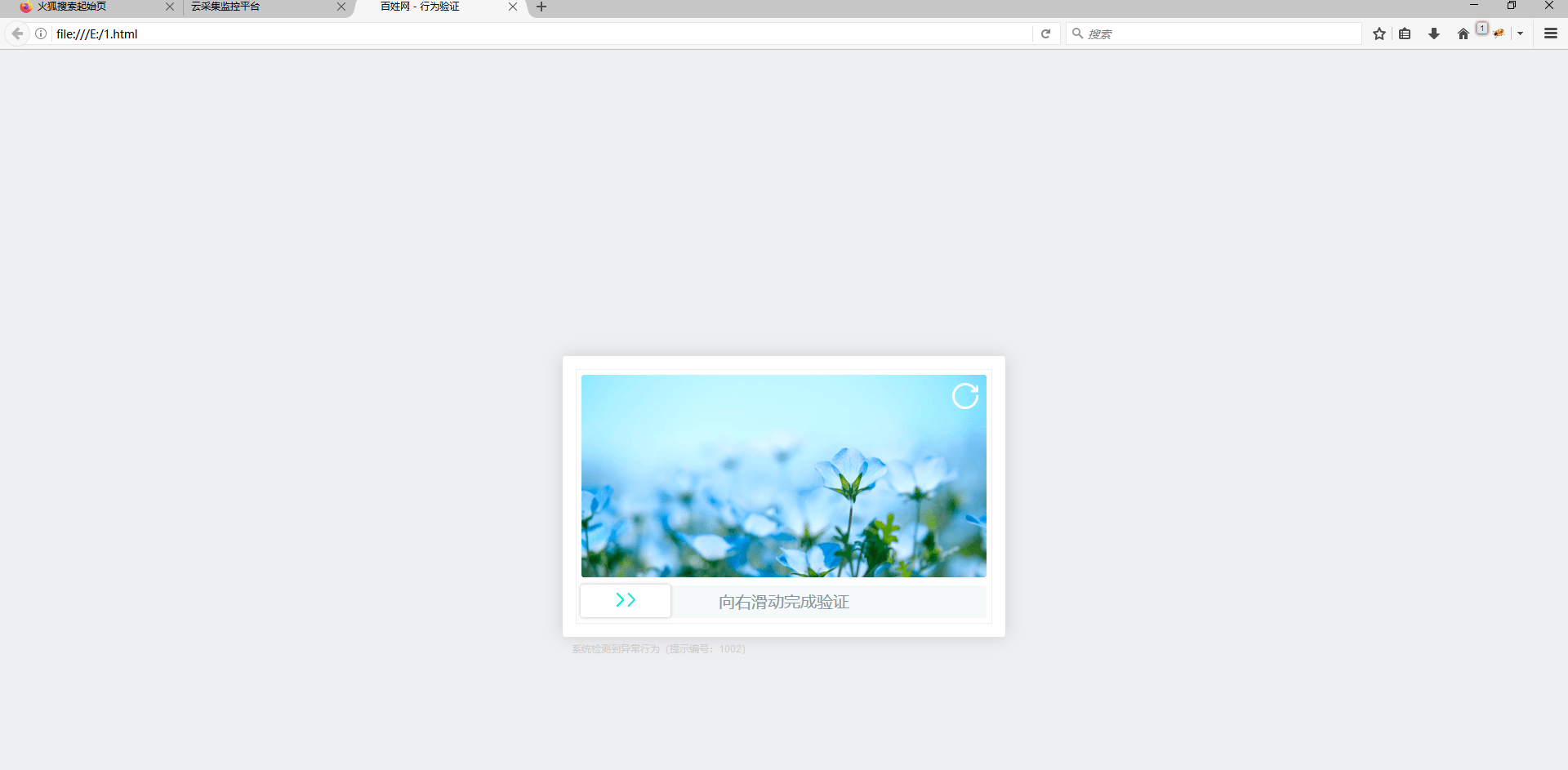
防采集主要是以下三类:IP被封禁止访问、出现验证码、云上需要登录 针对以上三种情况,都可以通过采集网页的html源码进行观察,这里我们以百姓网招聘数据采集为例。如下图1所示启动云采集后子任务出现采集为0的情况。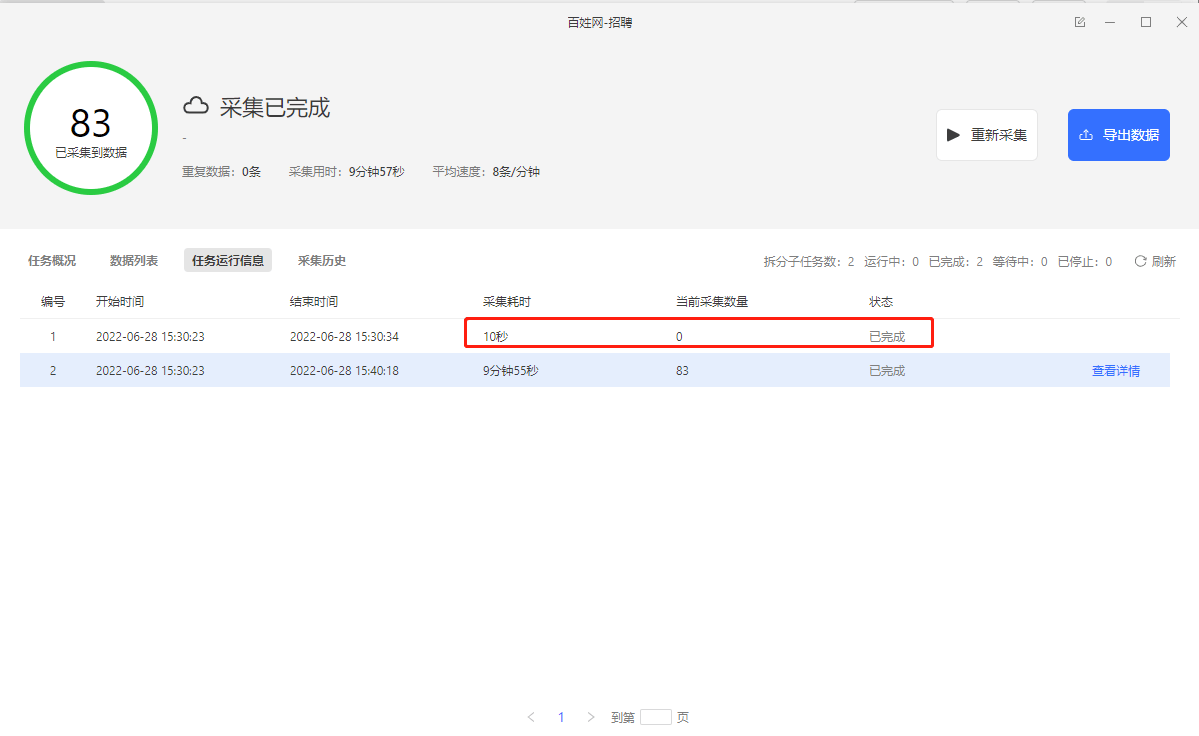
二、网站或网速原因
如果网站未完全打开,则显示下图高亮处: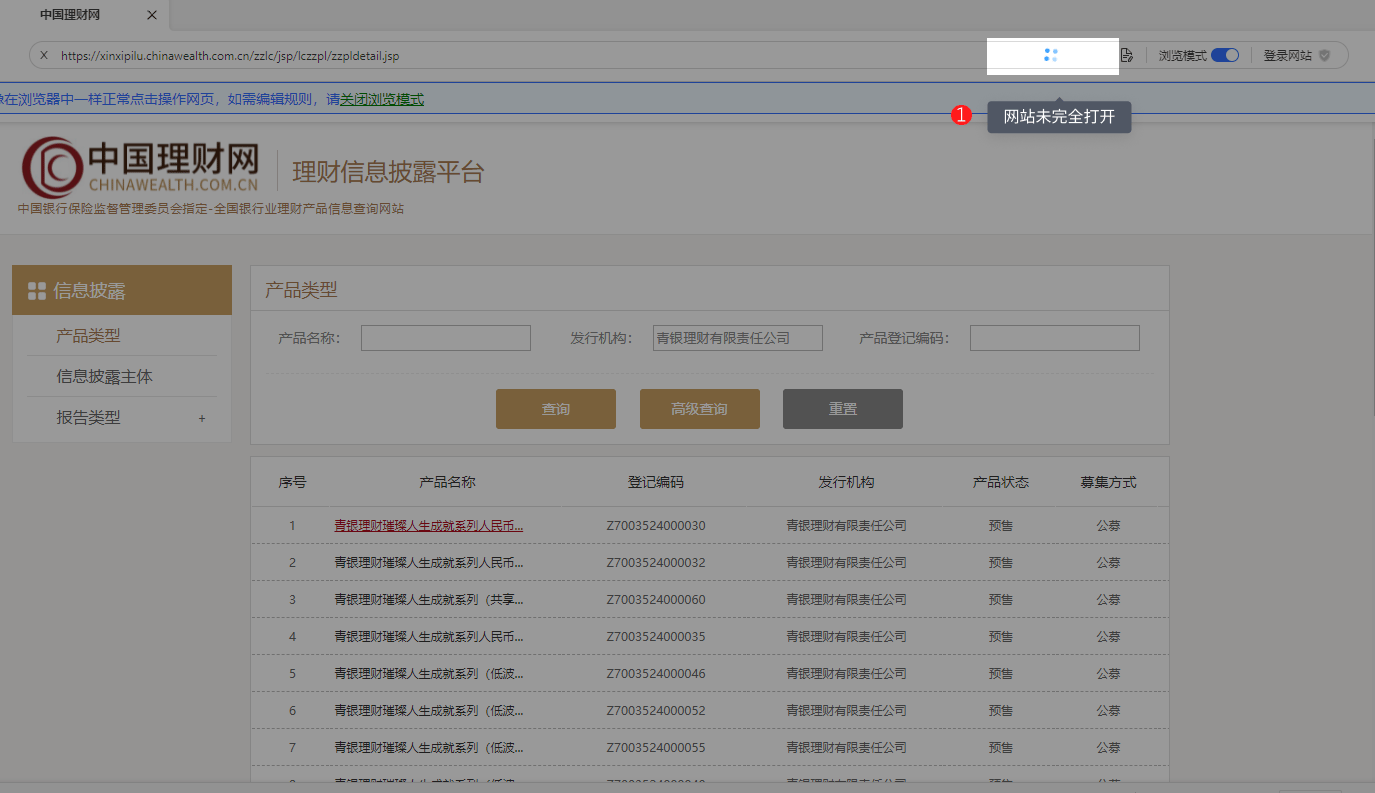
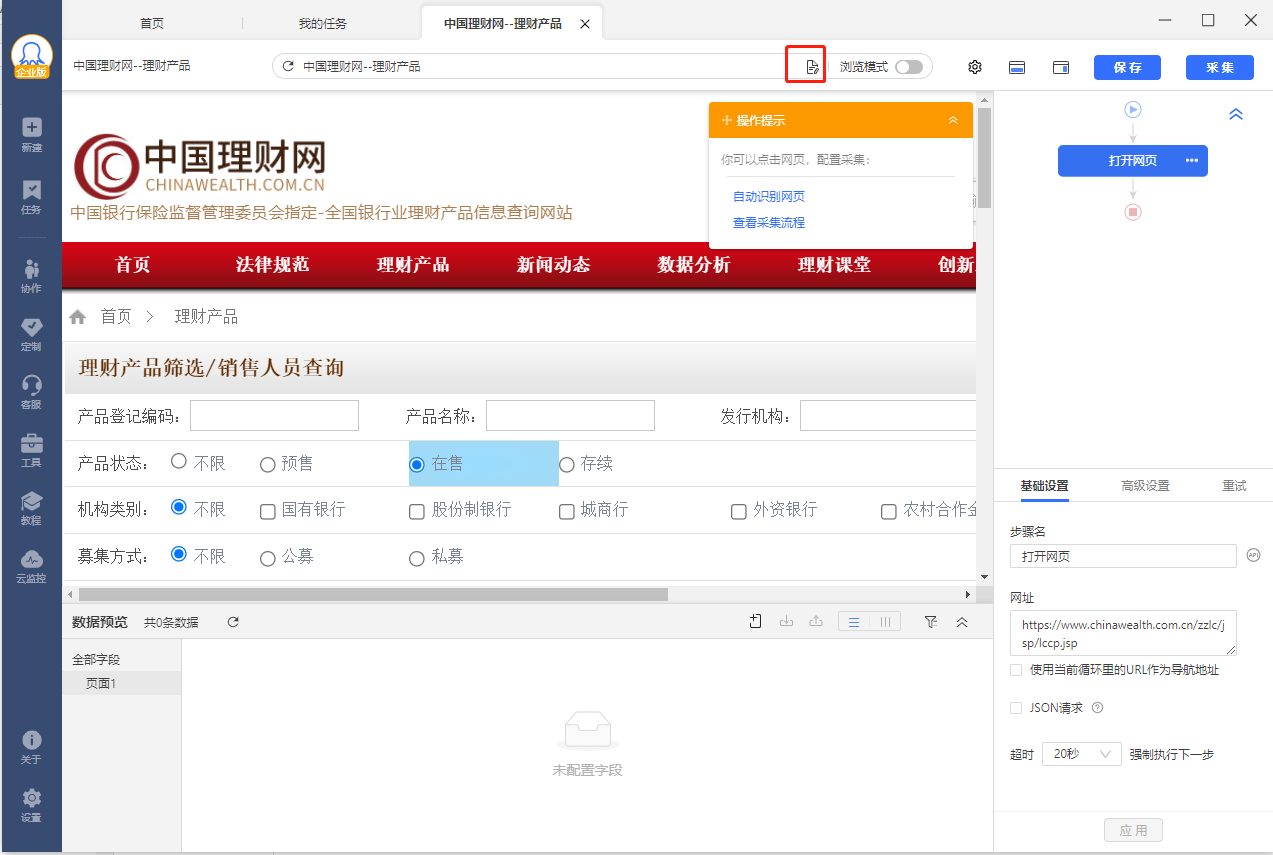
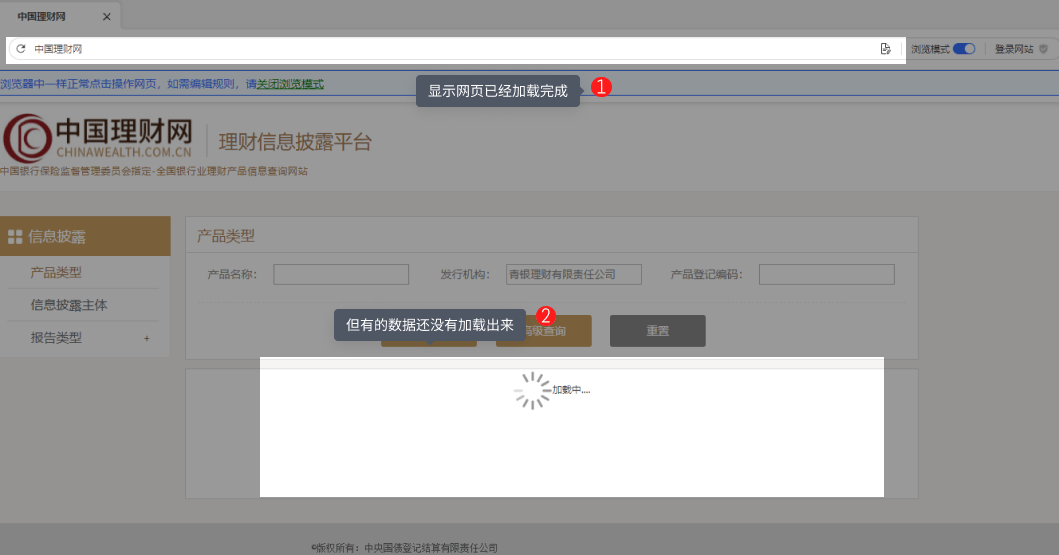
三、网络环境不同,源码有变,原xpath定位不准
部分网站在不同环境下打开网页源码会有变化,从而导致在本地采集是正常,但是在云上xpath定位不准导致采集不到数据。此类情况的解决办法如下: 1.用前面采集网页html源码的方法,采集网页的源码后保存为.html文件,然后再火狐浏览器中打开文件。 2.然后修改字段的xpath 这里修改xpath需要学习掌握xpath的知识 xpath的知识四、网站只允许单浏览器或单IP登录
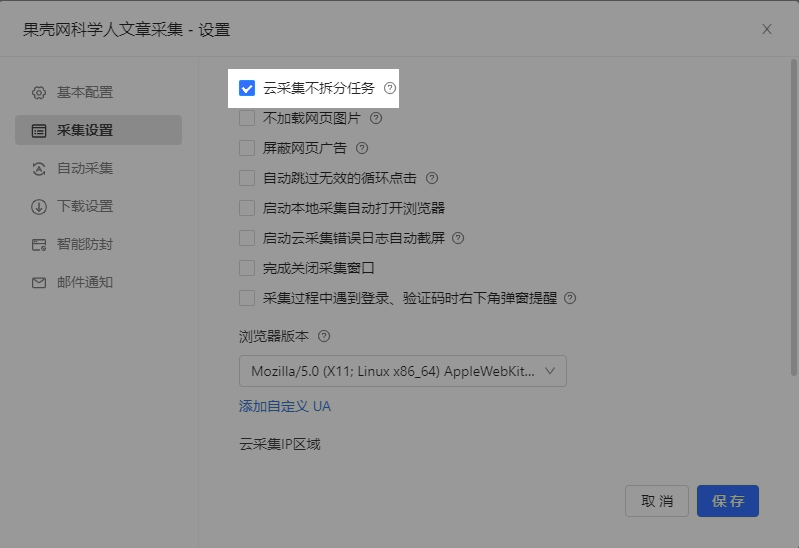
网站只允许单浏览器或单IP登录,如果任务进行了拆分会导致云采集不到数据。解决的办法:设置云采集不拆分。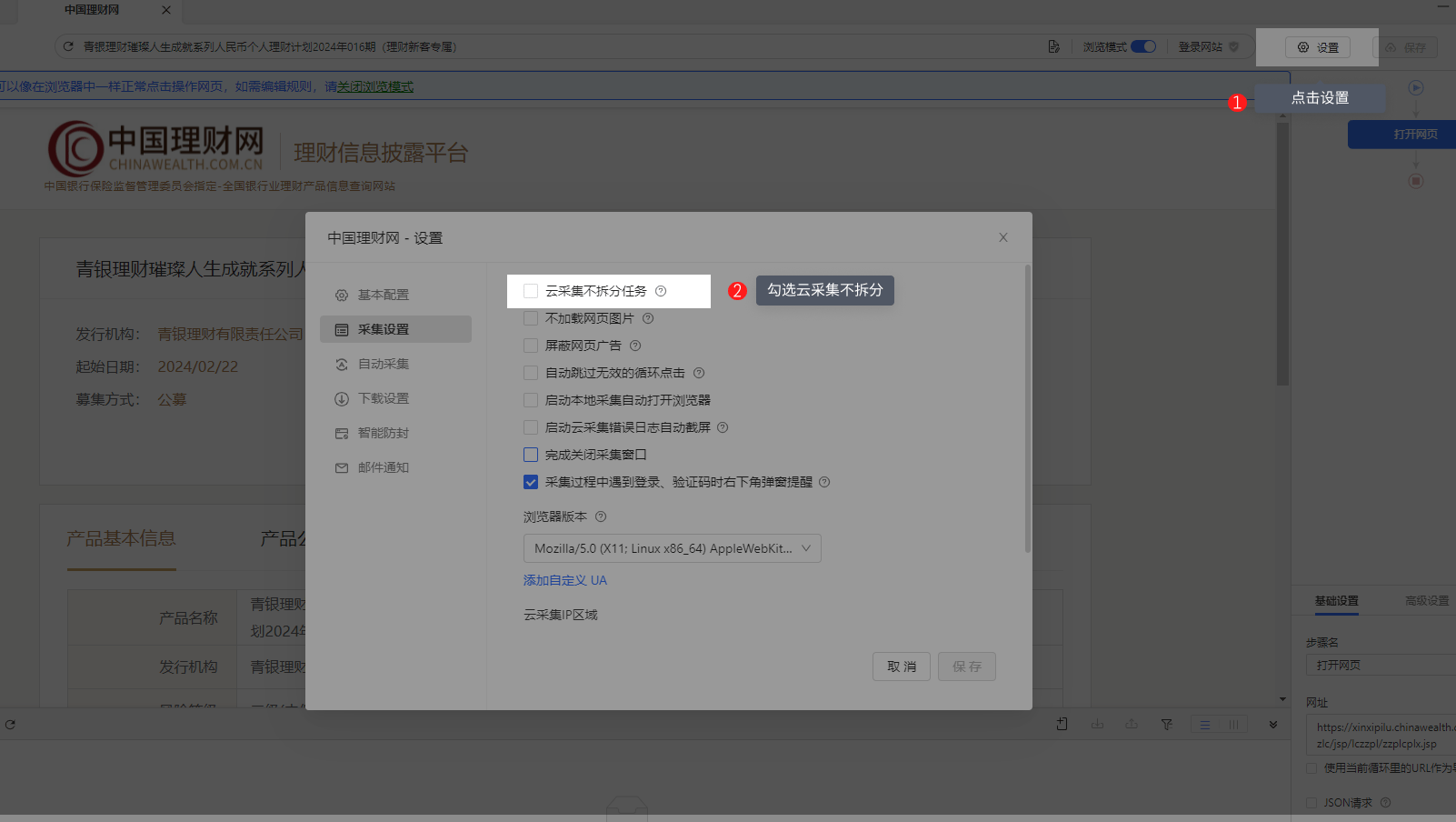
五.规则问题-增量采集
原因:云采集具有增量采集功能:根据url判断是否采集过,第一次采集后,后续不会再采集已采集过的url。如果是列表信息采集,如果后续有增加新增列表,但url没有发生改变,八爪鱼会跳过此条url不采集 解决方法:关闭增量采集。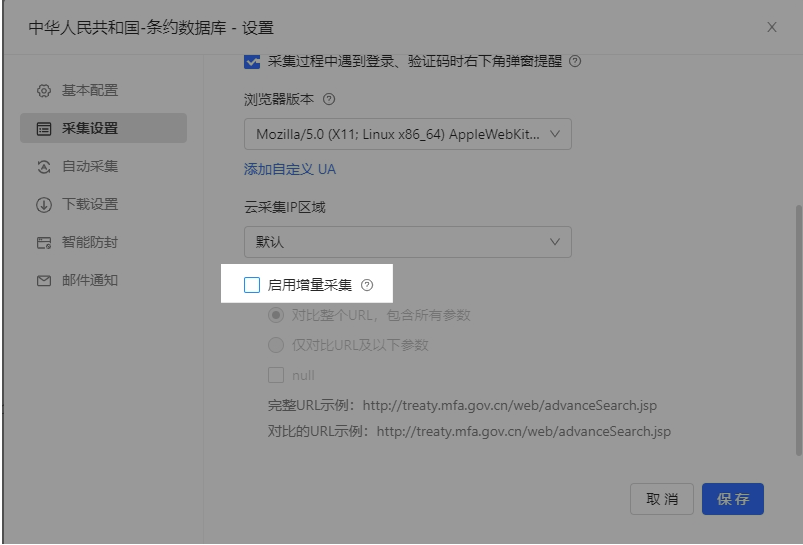
六、快速排错的小技巧
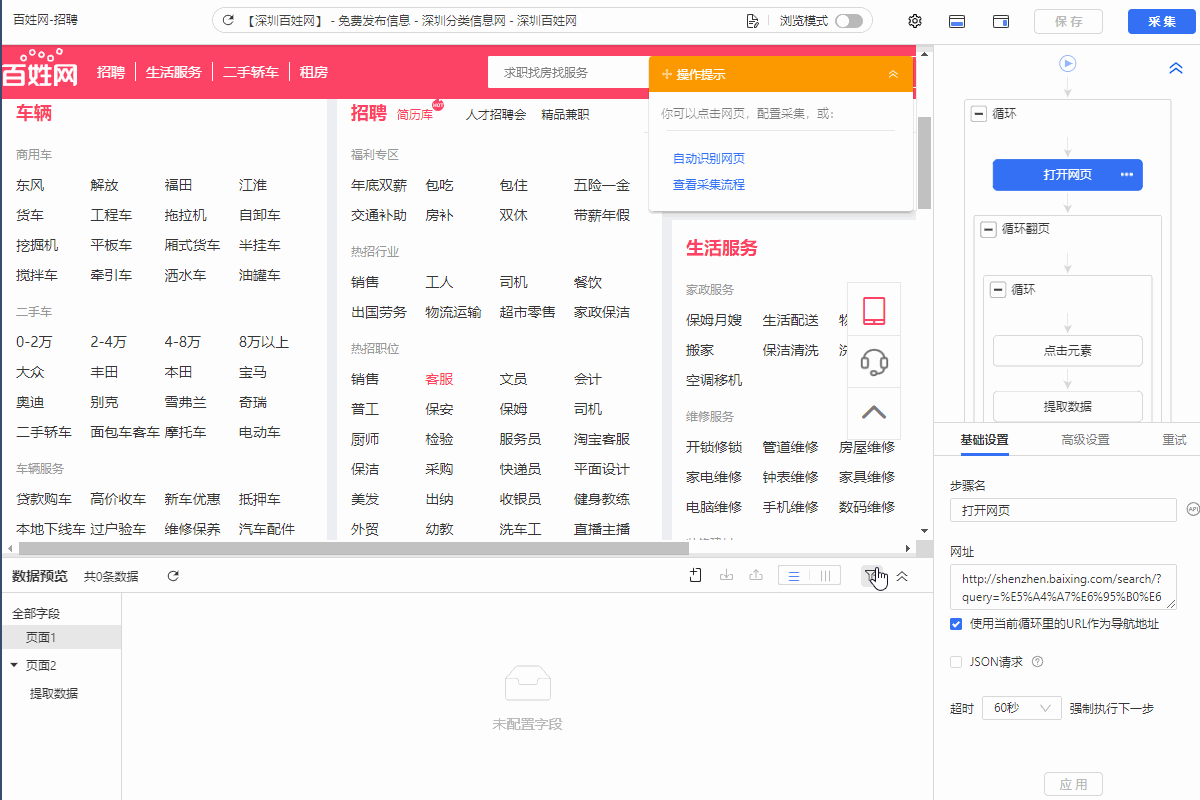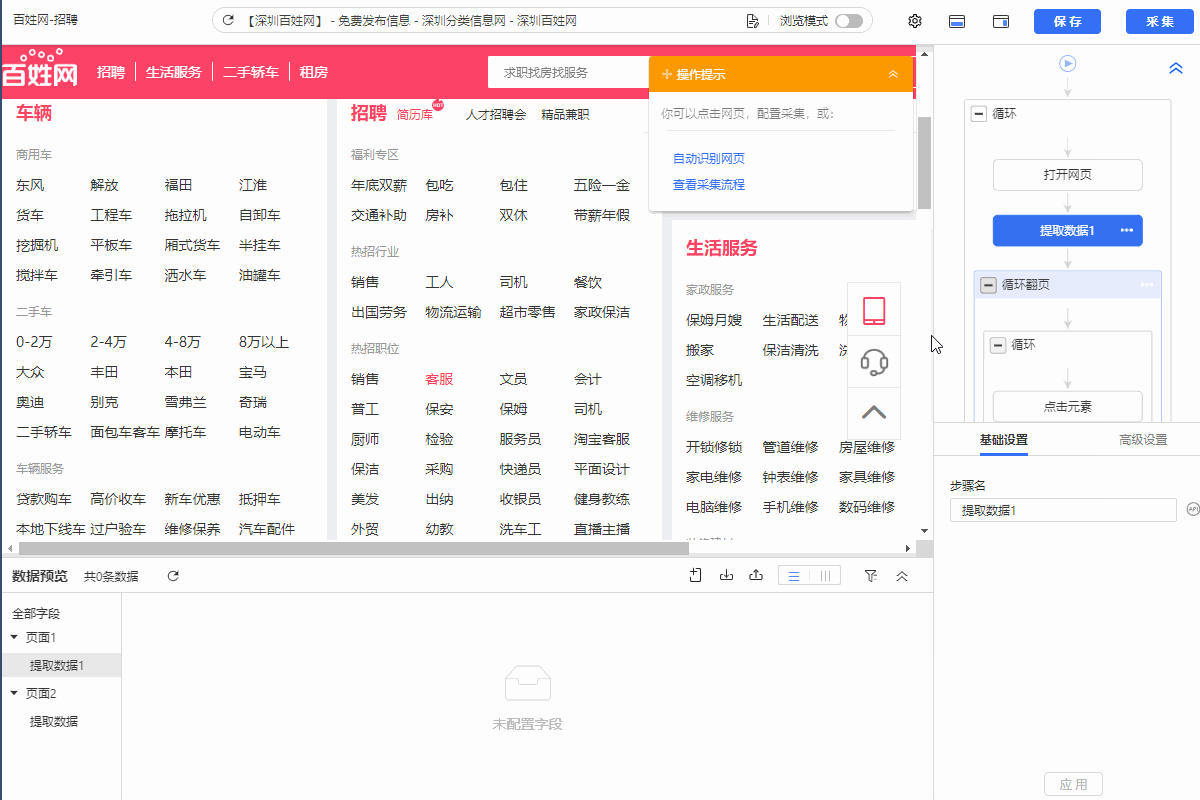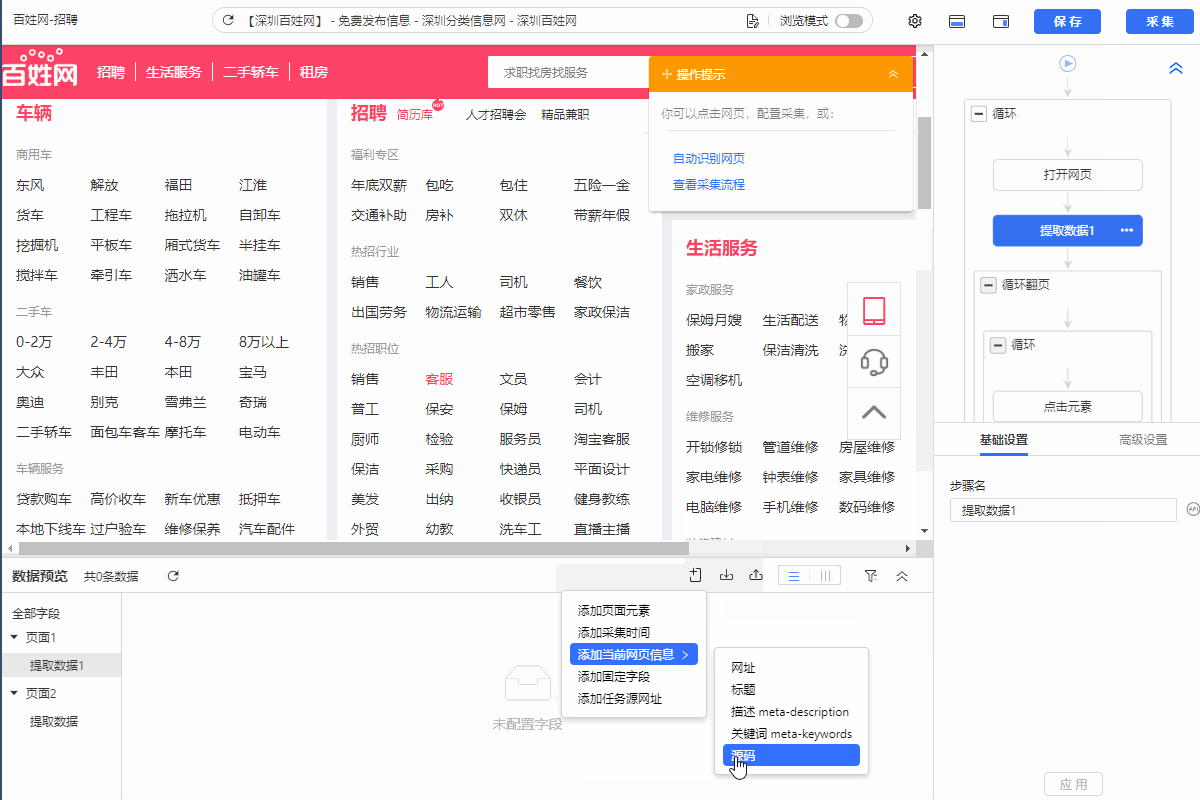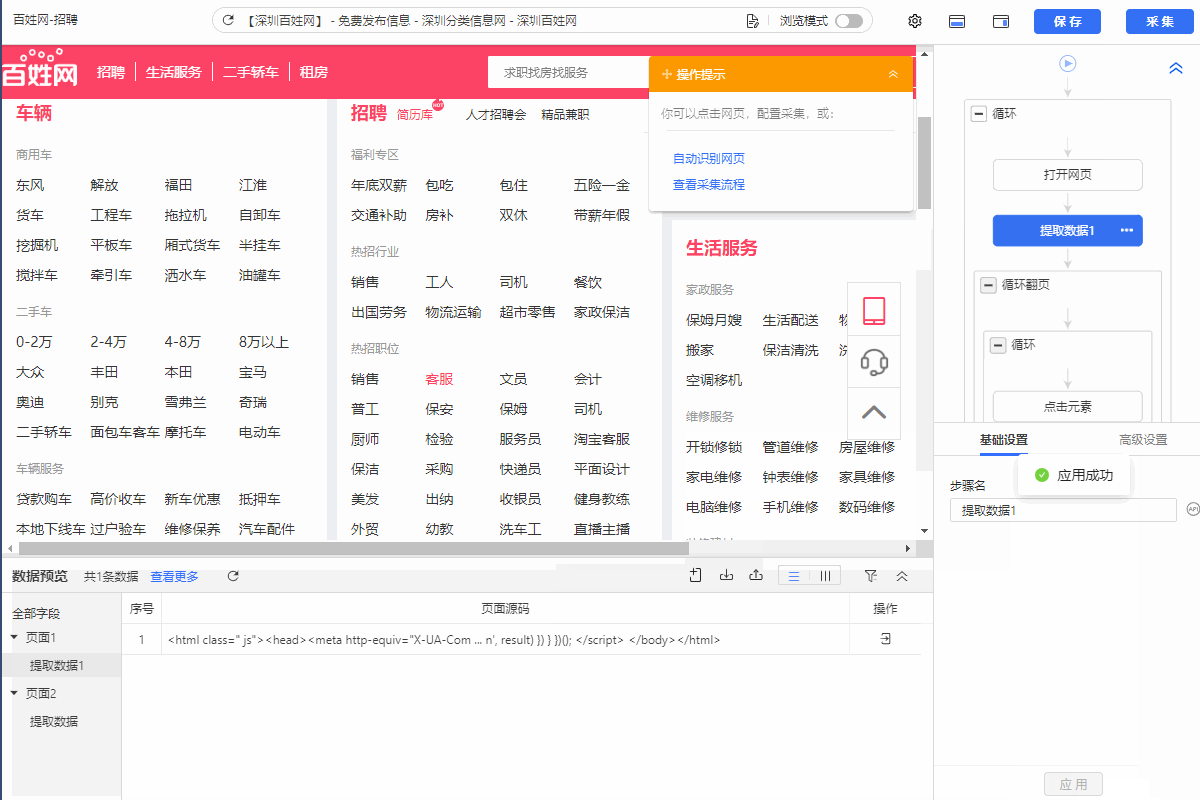
1、提取数据增加提取网页页码 帮助我们快速定位数据采集从哪一页开始出现问题 2、提取数据增加提取网页网址 提取不到字段时,帮助我们快速检查网页情况,是网页本身的问题(网址失效、本身无此字段),还是八爪鱼问题(无法正常打开网页、XPath定位不准等) 3、提取数据增加提取网页源码 常见于云采集,便于我们查看采集任务在云上的运行环境。