① text() 用文本定位位置
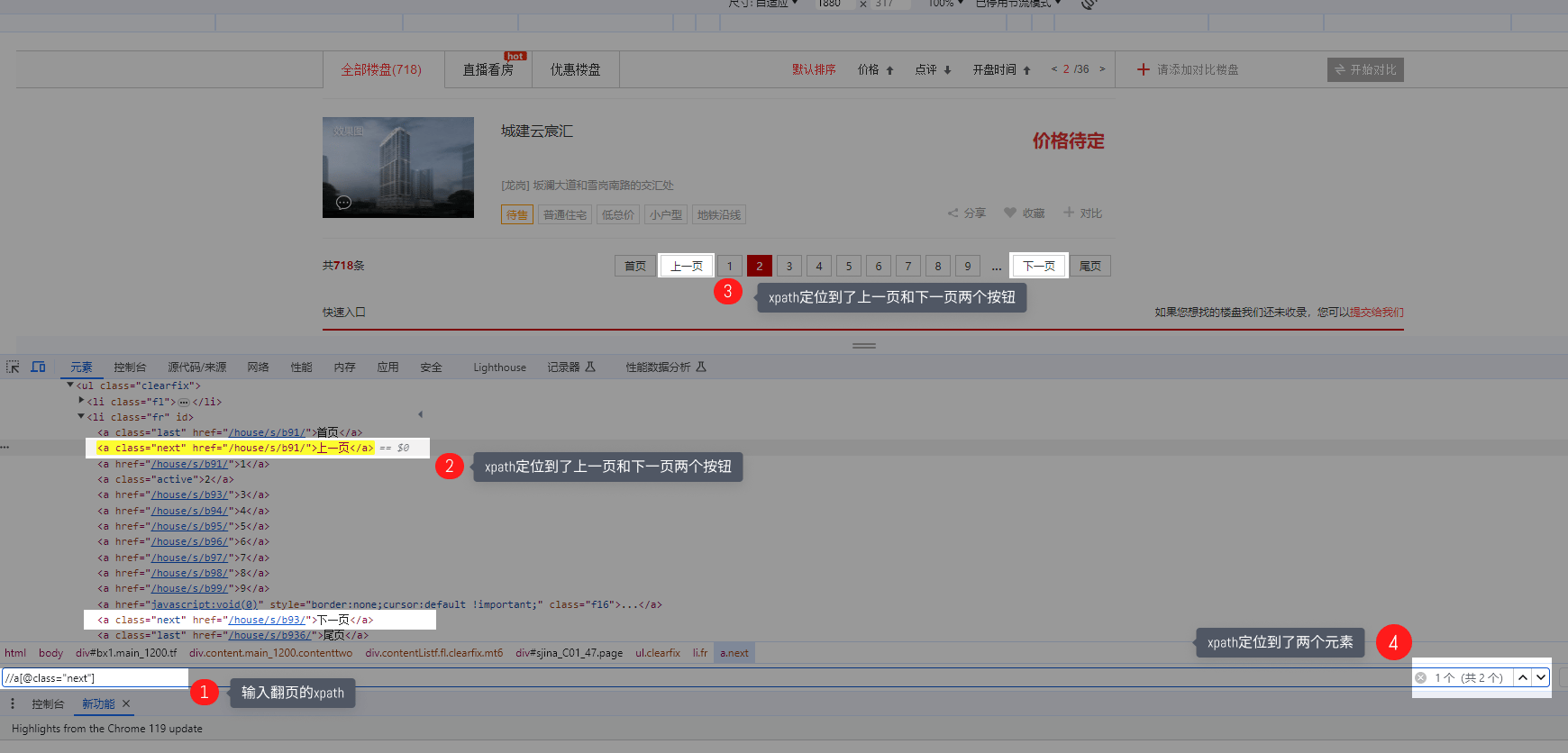
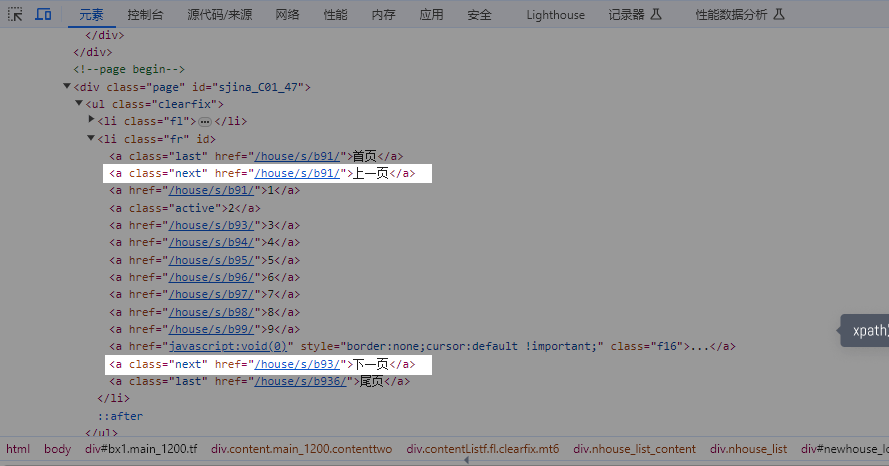
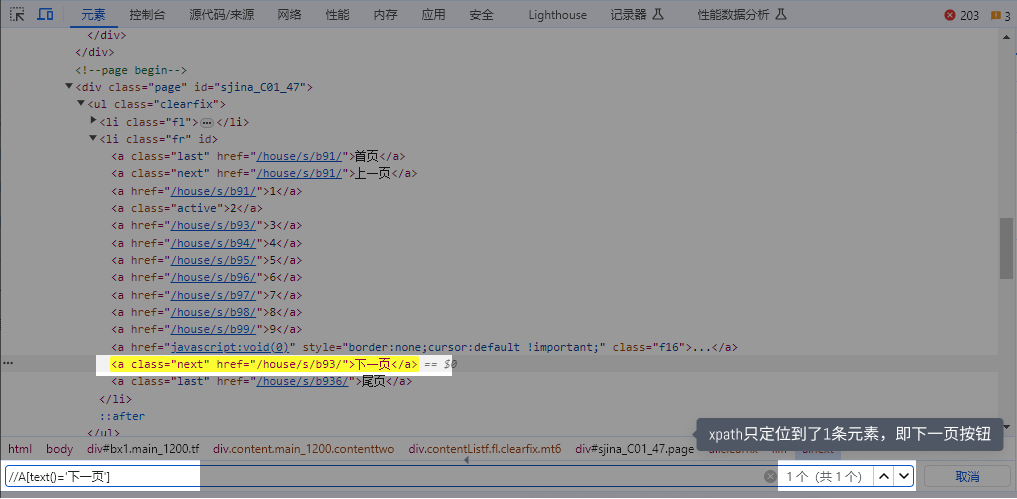
text()=‘xxx’ 精确定位,引号中的内容需与HTML文档中的文本完全一样 contains(text(),‘xxx’) 模糊定位,HTML文档中的文本,包含引号中的内容即可 如果需要定位到此网页中的【后页>】按钮。 用 text()=‘xxx’ 定位,则XPath为: //a[text()=‘后页>’] ,引号中的文本一定要为 ‘后页>‘,如果换成 ‘后页’ (少了一个>),则定位不到【后页>】按钮。
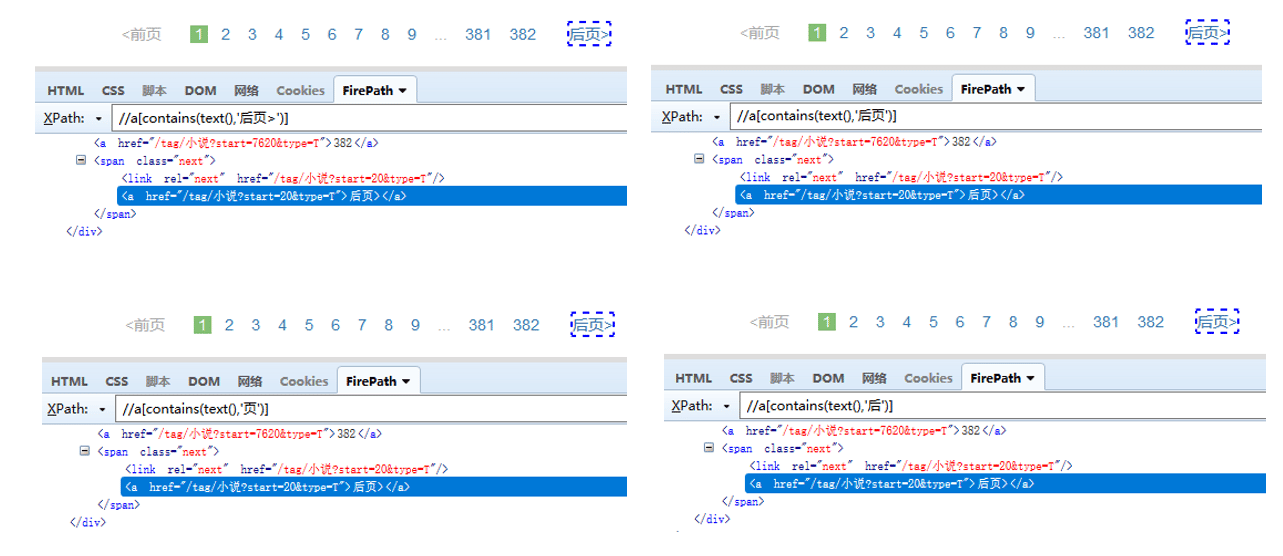
② contains() 用于判断文本的一部分是否包含XXX,或者属性值是否包含XXX
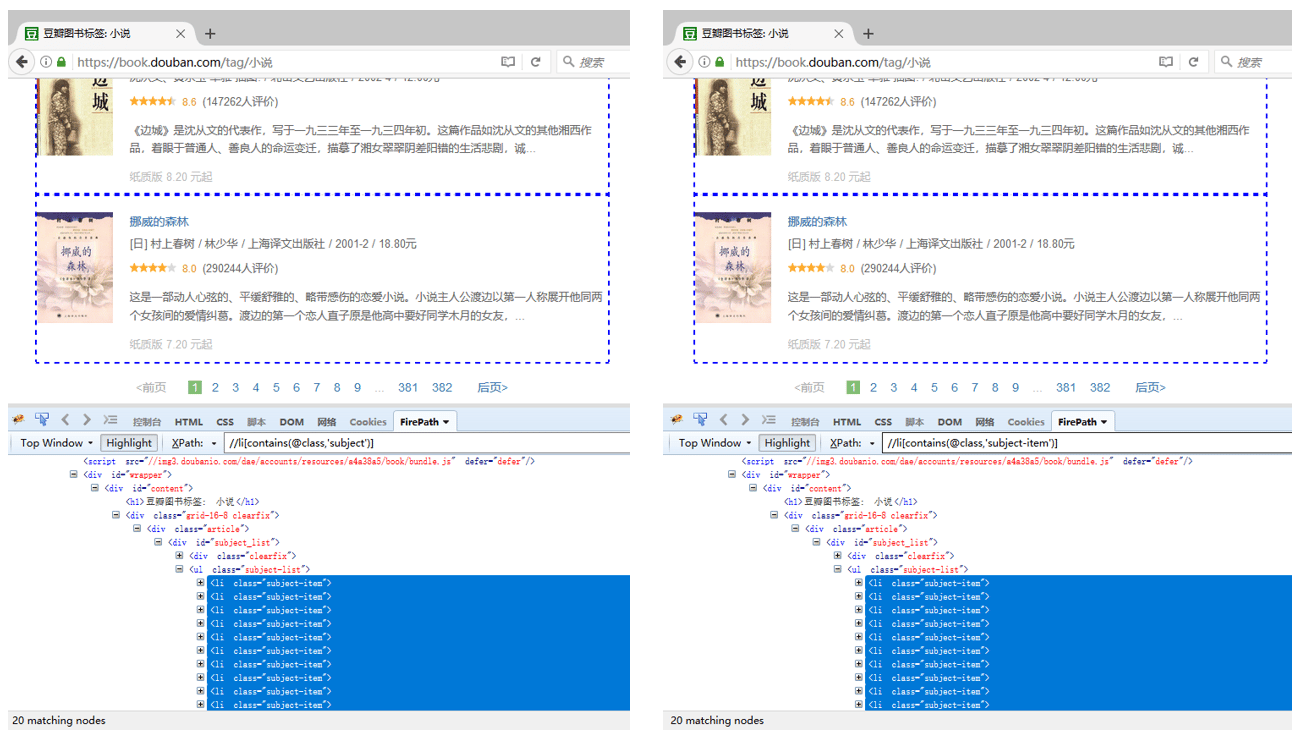
contains(text(),‘xxx’) 判断文本的一部分是否包含XXX,上面已经详细说明 contains(@class,‘xxx’) 判断属性值是否包含XXX 如果需要定位到此网页中的所有图书列表。 直接用属性定位,则XPath为: //li[@class=‘subject-item’] ,引号中的属性值一定要为 ‘subject-item’,跟HTML文档中的属性值完全一致。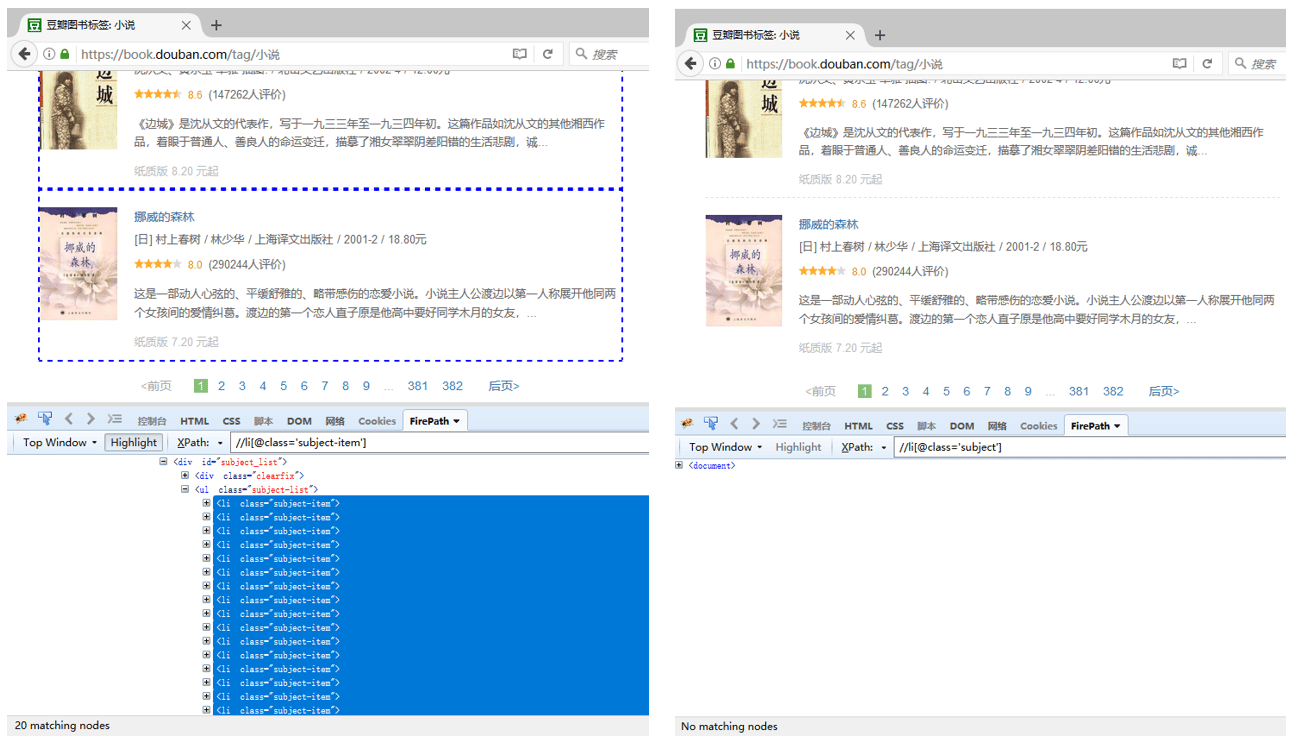
③ position() 用于定位节点的位置和限制节点的范围
position()=1 同级标签的第1个 position()>1 and position()<10 同级标签的第2-9个 常用于控制循环列表的项。如图, //ul[@class=‘subject-list’]/li[position()>1 and position()<10],定位的是第2-9个li标签。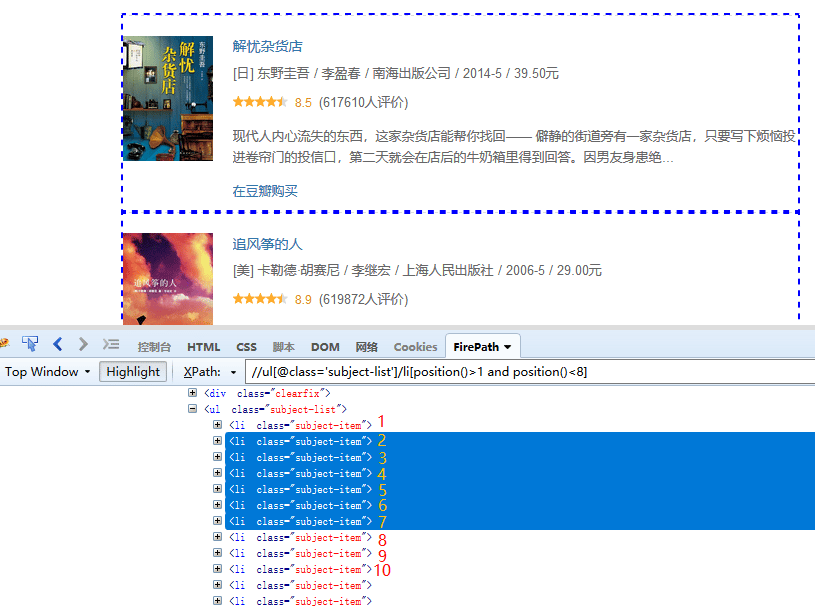
④ last() 最后1个
last() 最后1个标签 last()-1 倒数第2个标签 last()-2 倒数第3个标签 如图, //ul[@class=‘subject-list’]/li[last()],定位的是最后1个li标签。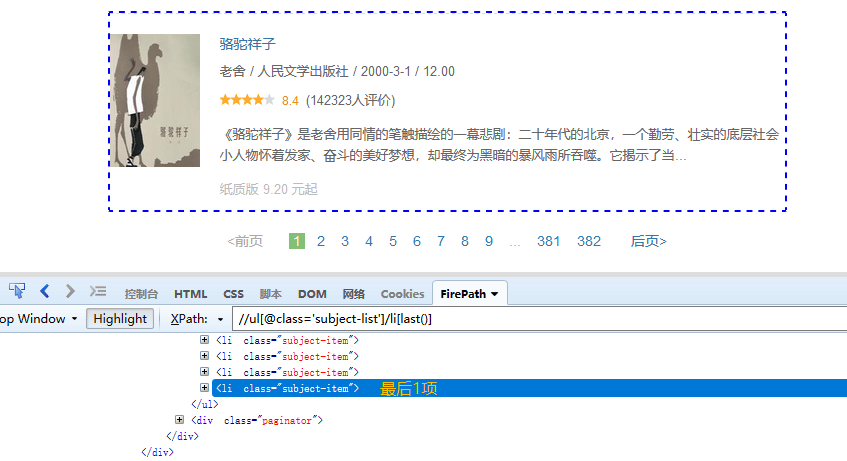
⑤ and/or/not 同时满足/满足其中1个即可/无
and 且,同时满足 a[@class and @href] 既有class属性,又有href属性的a标签 or 或,满足其中1个即可 a[@class or @href] 有class属性,或者有href属性的a标签 not 无 a[not(@class)] 不含class属性的a标签⑥ following-sibling:: 选取当前节点之后的所有同级节点
在八爪鱼中常用于数字翻页,点击查看 数字翻页教程。 如图, //span[@class=“thisclass”]/following-sibling::a ,定位到span节点之后的所有同级a节点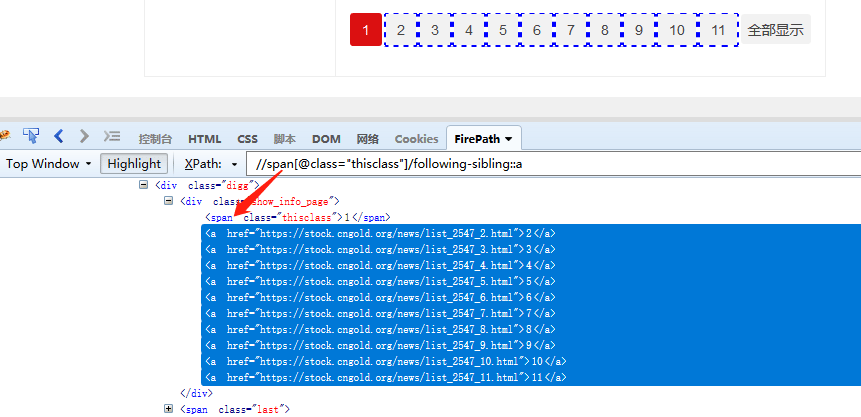
⑦ preceding-sibling:: 选取当前节点之前的所有同级节点
如图, //a[@target=’_blank’]/preceding-sibling::strong ,定位到a节点之前的所有同级strong节点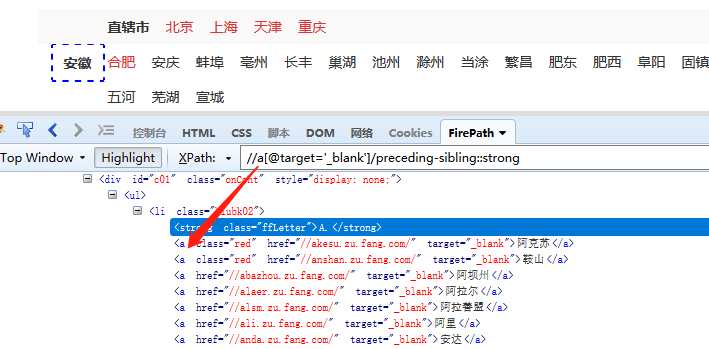
实战演练
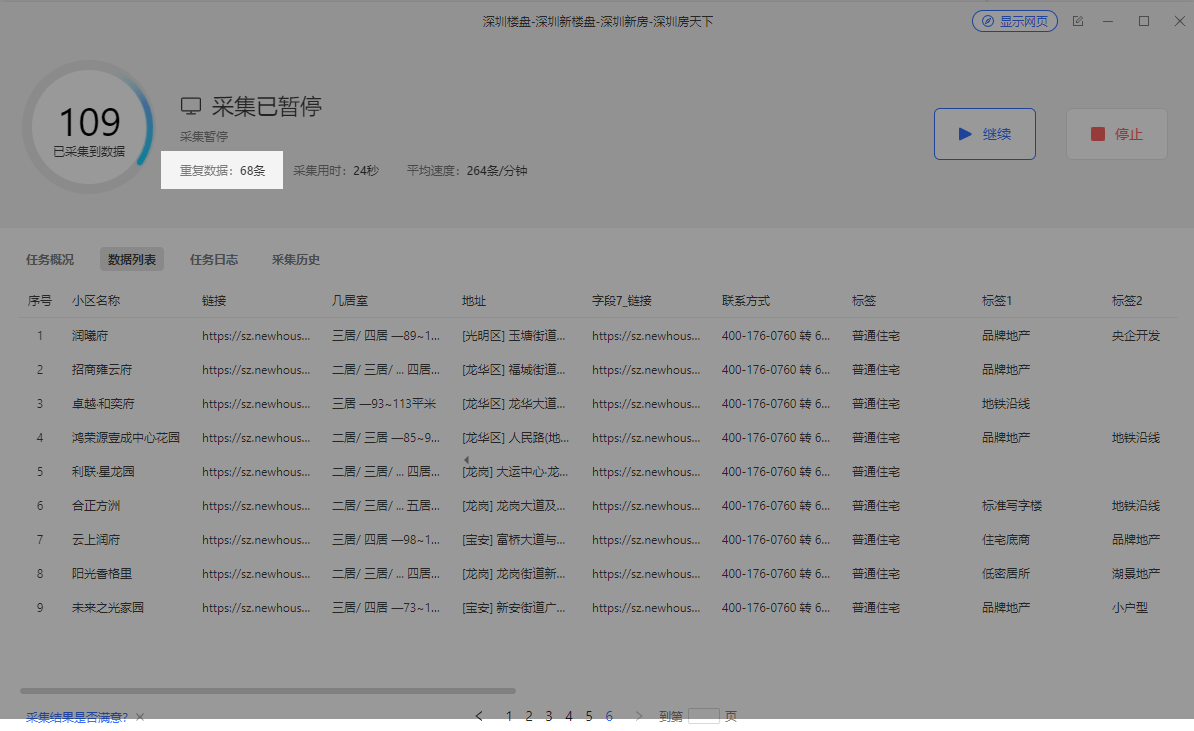
题1:采集以下网址,全部的列表数据。 http://newhouse.sz.fang.com/house/s/b91/?ctm=1.sz.xf_search.page.1 1、按照 列表采集 和 翻页 的方法,配置采集规则。 2、按需求编辑采集下来的字段,如图。 3、启动采集,我们发现,有非常多的重复数据。观察重复数据发现,是从第2页后开始重复的。为什么?