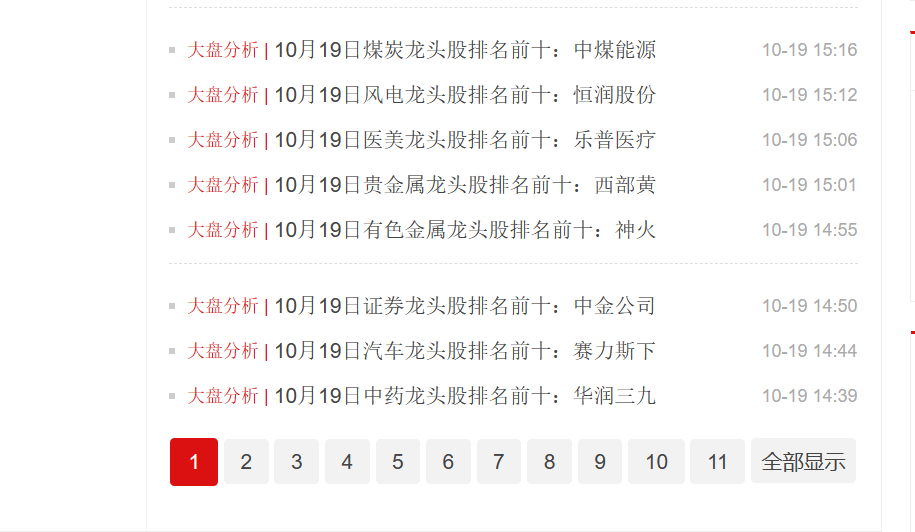
一、使用智能识别实现【数字翻页】
八爪鱼的智能识别,支持【数字翻页】的智能识别,如下视频所示:二、自己配置采集流程实现【数字翻页】
如果想了解背后的原理,我们可以来尝试自己配置这类网页的采集流程。 让八爪鱼不断点击数字进行翻页:当前页是第1页,点第2页;当前页是第2页,点第3页…当前页是最后1页,结束【循环翻页】。 所以问题的关键是:需要写一条XPath,使其始终能定位到当前页的下一页(最后1页除外)。需要大家有一定的XPath知识,点击学习 XPath入门 。以下为具体步骤。 Step1. 写一条XPath,使其始终能定位到当前页的下一页(最后1页除外)。分2步:先定位到当前页;再定位到当前页的下一页。 先定位到当前页。 当前页分别是第1页、第2页、第3页…最后1页时,观察网页源码的特征。我们发现:当前页的源码是span标签,而其他页则是a标签。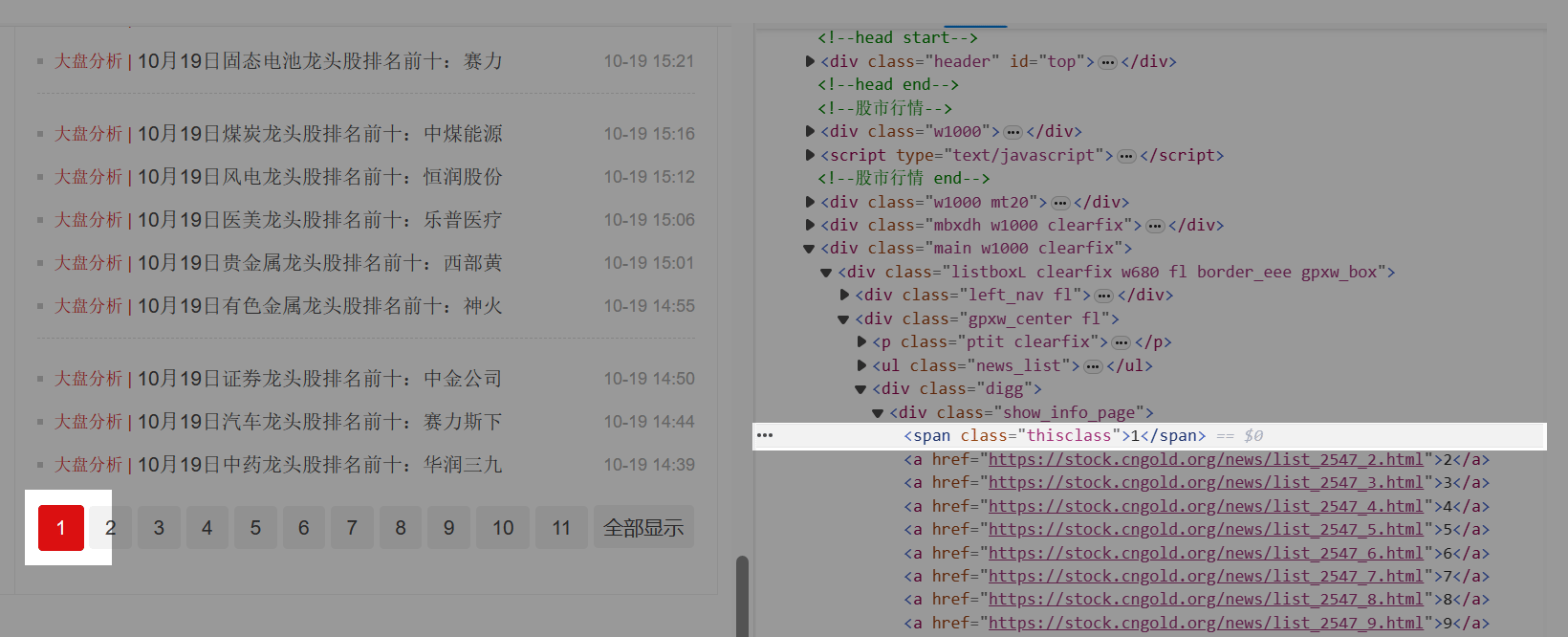
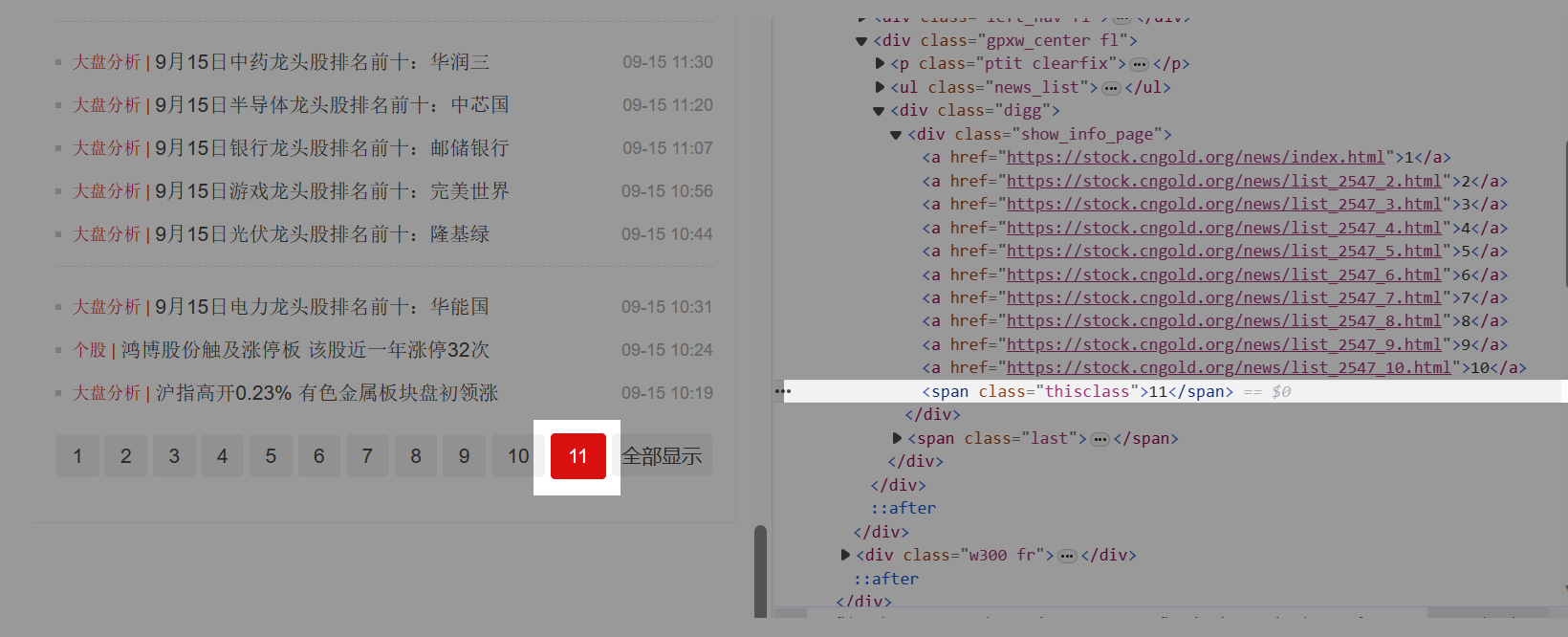
特别说明: a. 这个网页,当前页和其他页的源码区别非常明显。但有的网页可能没这么明显,请大家耐心去找到当前页和其他页的源码区别。继续观察当前页源码中span标签的特征,找到具有唯一性的那个特征。我们发现,当前页对应的span标签,具有class属性,且class属性的属性值为thisclass。根据这个特征,写出一条定位XPath://span[@class=“thisclass”] 。 检查后发现,能定位到每个当前页。
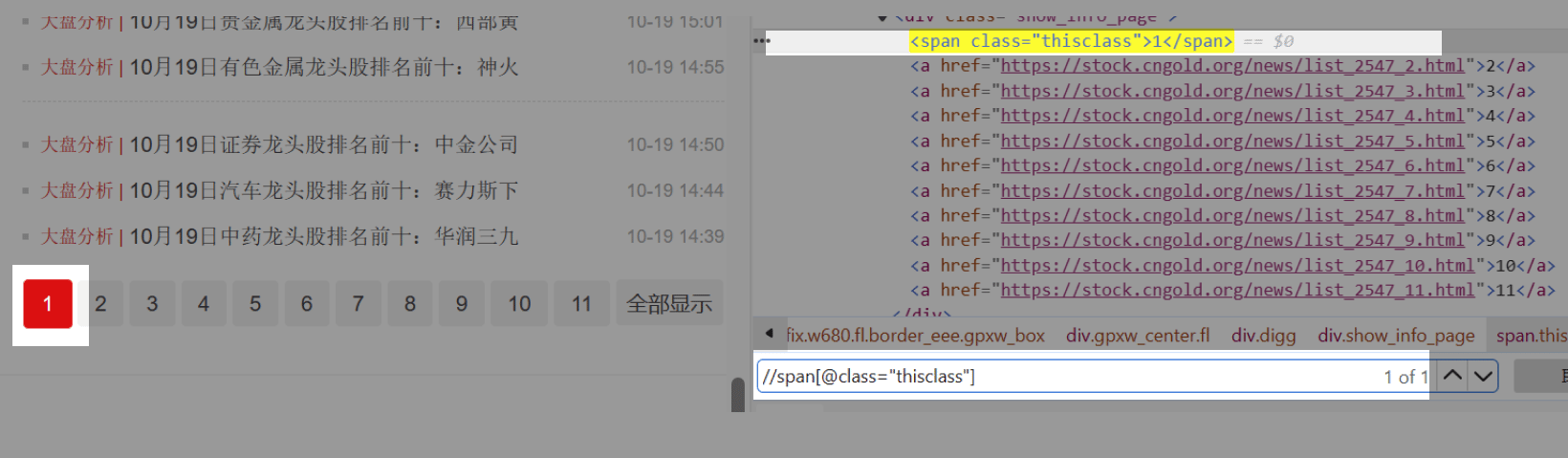
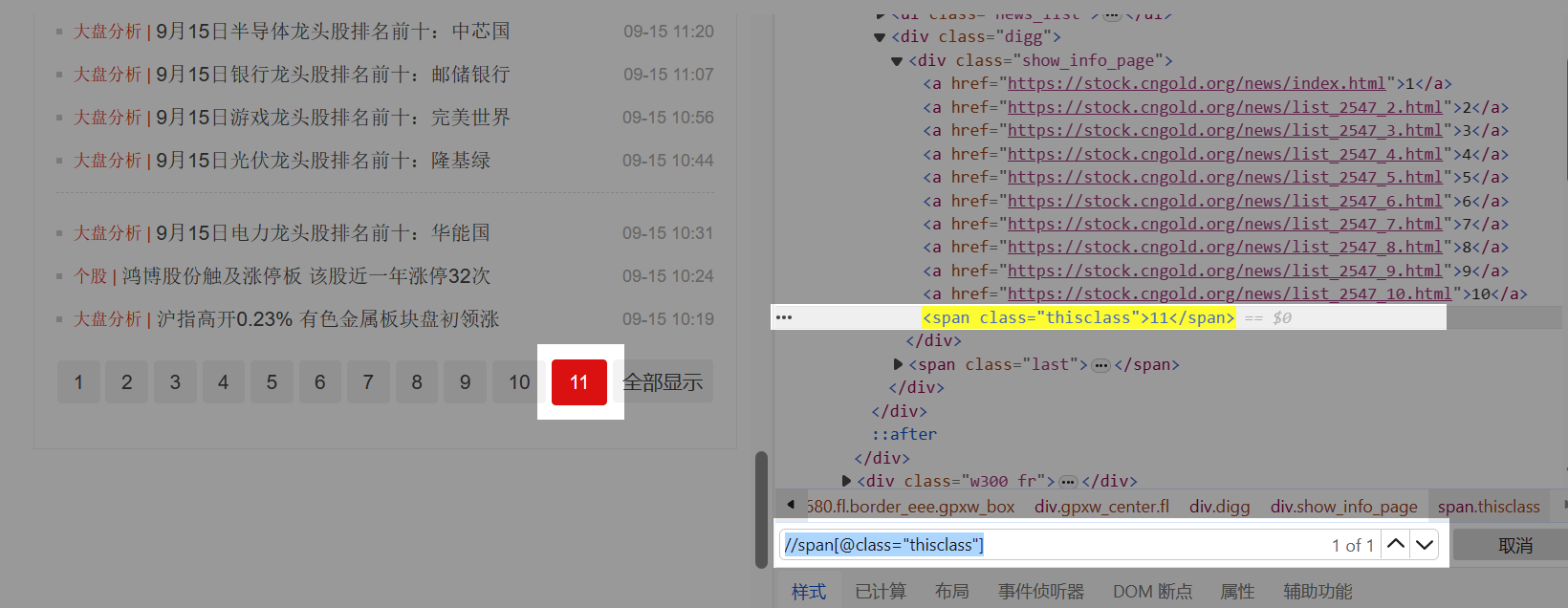
a. 什么是同级标签?HTML文档是树状结构,标签之间具有层级性。同级标签即处于同一层级的标签。
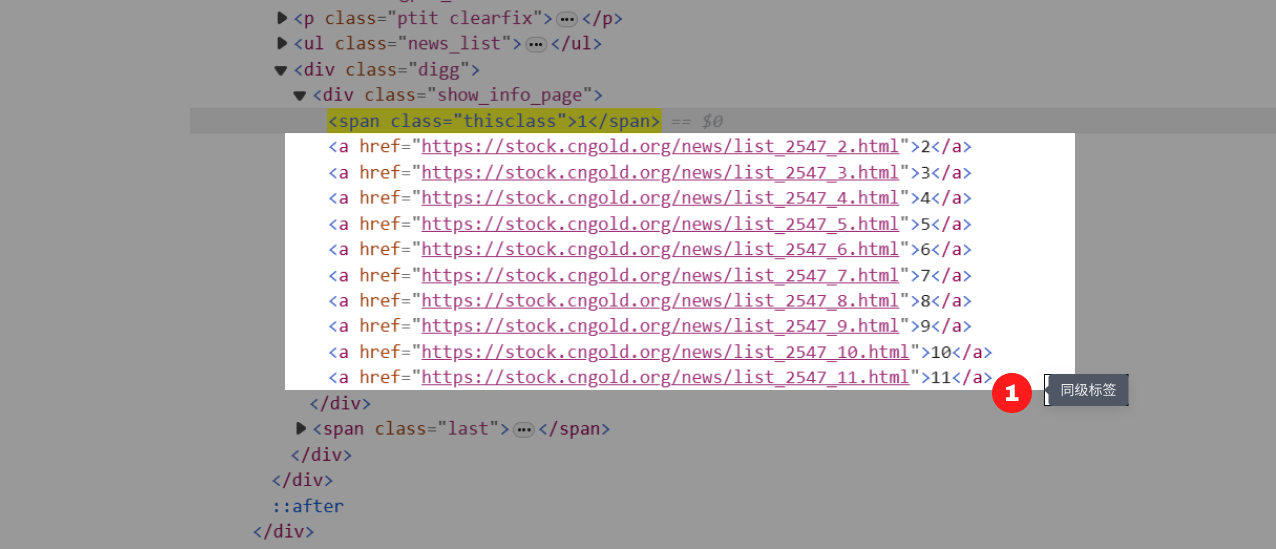
 Step2. 在八爪鱼中创建一个【循环翻页】。往流程中拖入一个【循环】步骤,选择循环方式为【单个元素】,将上面写好的XPath://span[@class=‘thisclass’]/following-sibling::a[1],复制到【单个元素】后面的文本框中,点击【确定】保存。
再往【循环】里面拖入一个【点击元素】的步骤,设置Ajax超时时间为7秒,然后点击【确定】保存。手动执行一个规则,发现可正常翻页。
为什么要设置Ajax?点击查看 Ajax教程 。
接下来就是按需提取数据了,不再赘述。
Step2. 在八爪鱼中创建一个【循环翻页】。往流程中拖入一个【循环】步骤,选择循环方式为【单个元素】,将上面写好的XPath://span[@class=‘thisclass’]/following-sibling::a[1],复制到【单个元素】后面的文本框中,点击【确定】保存。
再往【循环】里面拖入一个【点击元素】的步骤,设置Ajax超时时间为7秒,然后点击【确定】保存。手动执行一个规则,发现可正常翻页。
为什么要设置Ajax?点击查看 Ajax教程 。
接下来就是按需提取数据了,不再赘述。