
如何利用ChatGPT撰写正则表达式辅助数据采集?
先做一个小调研:爪子们在日常采集中会经常用到正则表达式吗?比如调整网页既定格式;剔除多余符号等…..

正则表达式的强大毋庸置疑,但使用门槛也确实存在。
即便是采集熟手,想要通过正则匹配准确拿到想要的信息,有时也要经过多次尝试,更不用说刚刚接触八爪鱼采集器的小白了。

正则匹配前
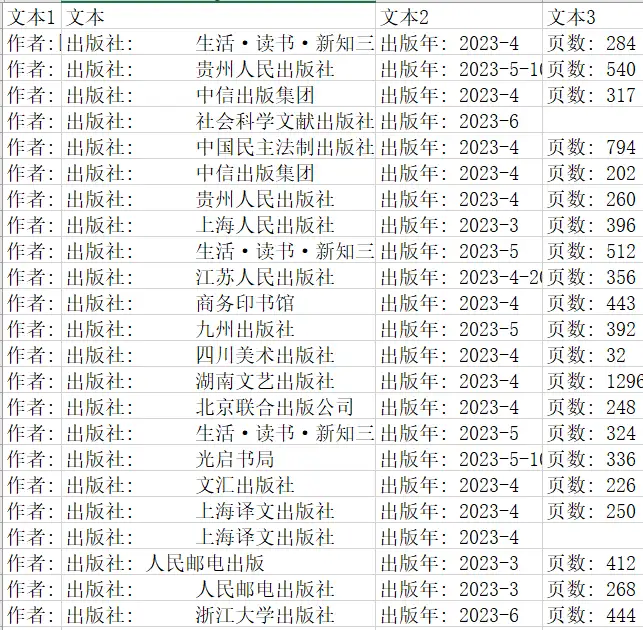
正则匹配后
正则表达式是什么?
正则表达式是一种字符串匹配的模式,用于描述一类字符串的集合。它可以用来匹配、搜索、替换、验证等操作,广泛应用于文本处理、编程语言、数据库等领域。
具体来说,正则表达式可以用特定的符号和字符组合来匹配不同的字符串模式。如:
– \d 表示任意一个数字字符
– * 表示重复零次或多次
– + 表示重复一次或多次
– ? 表示重复零次或一次
– \w 表示任意一个字母、数字或下划线字符- . 表示任意一个字符
– [] 表示一个字符集,例如 [abc] 匹配任意一个字符 a、b 或 c
– () 表示一个分组,可以对其中的内容进行引用或者重复
当然以上这些只是正则表达式最基础的使用方式,通过这些符号和字符的组合,我们可以灵活构建各种各样的正则表达式来匹配不同的字符串模式,最终实现采集数据的调整。如:
表达式 \\s*(?=:\\s) 用于字段中删除冒号后的空格。
在这个表达式中,`\\s`表示任何空白字符,`*`表示零个或多个,`(?=…)`表示一个正向预查,它匹配括号中的表达式,但不将其包含在匹配结果中。
这个表达式用于匹配在冒号和空格之间的任何空格,意味着它不会删除字段值中的任意空格,只有在冒号后面有一个空格的情况下才会删除空格。
看到这里你是不是已经开始想放弃?

撰写正则表达式规则对新手来说确实会有较高的门槛,虽然八爪鱼也提供了正则工具辅助编写,但有时也需要多次尝试才能拿到最准确的信息。
但是!!现在有了ChatGPT,一切问题迎刃而解!
无须再自己编写,我们可以直接通过提问对话的方式获取所需规则!

如何用ChatGPT辅助采集?
本文小八将以豆瓣读书为例,讲解如何利用ChatGPT辅助八爪鱼实现数据采集。
举个栗子:
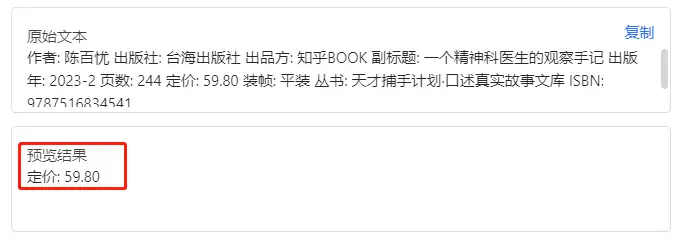
在采集过程中,我们只想要定价这个单独的数据,但选择元素时发现无法单独提取,只能和作者、出版社等数据合并选中,这种情况要如何用正则表达式实现?

Step 1 : 选中要格式化的文本
整个字段提取完成以后,鼠标移动到目标字段上,然后点击 【…】按钮,选择【格式化数据】,就会进入【格式化数据】配置页面。点击【添加步骤】,选择【正则匹配】。
Step 2 : 用ChatGPT获取正则表达式
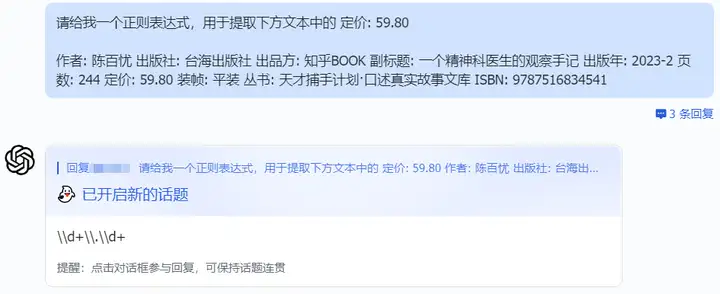
我们可以直接向ChatGPT提问:如何利用正则表达式提取出其中的部分信息?
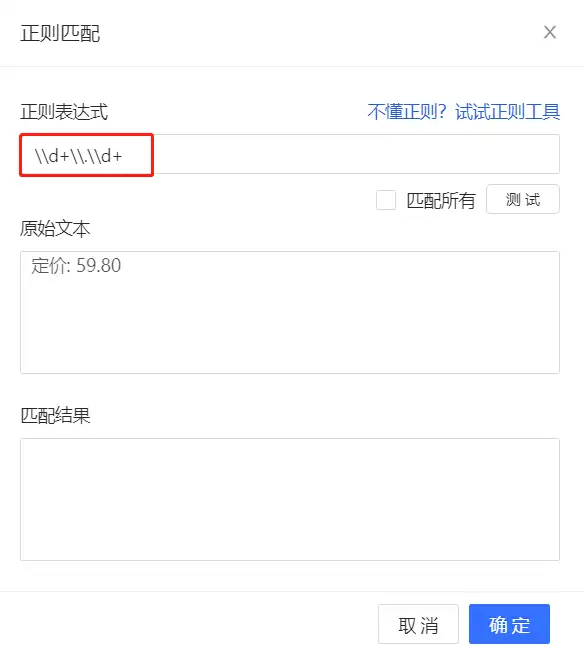
在添加步骤中直接输入表达式,但匹配结果显示为空,效果不佳。
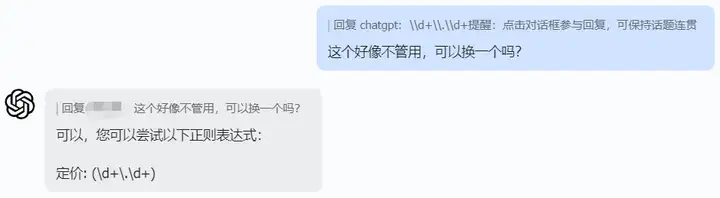
没关系,我们可以再次提问ChatGPT,此刻你就是硬气的甲方爸爸
再次尝试新公式,成功提取出想要的结果:
Step 3 : 利用正则表达式修改数据格式
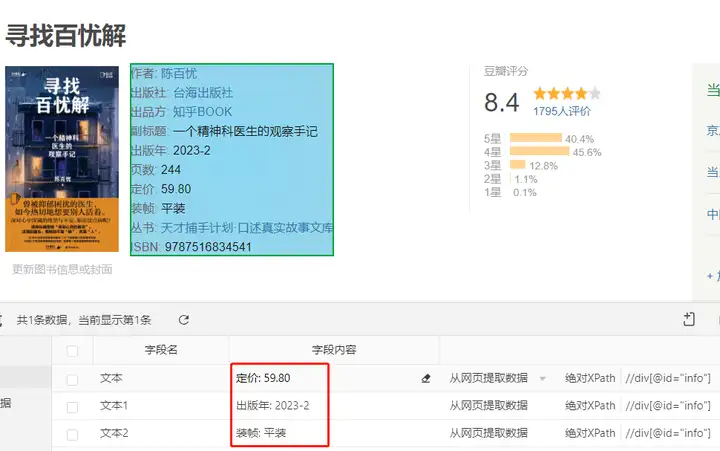
按这个流程,我们可以依次提取出出版年份,装帧方式等文本内容,成功拿到我们想要的数据啦~

除了正则匹配,ChatGPT也可以应用至正则替换等功能来剔除不符合规范的数据。
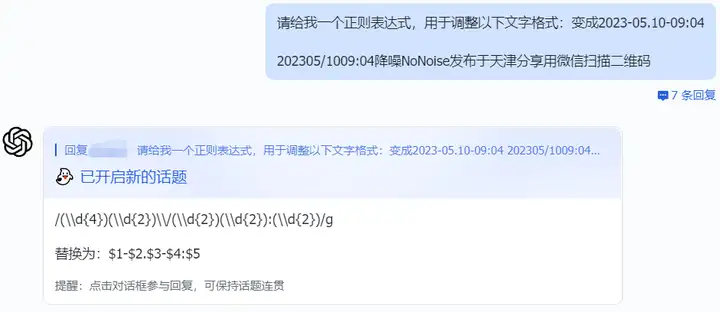
相比简单的【替换】,【正则表达式替换】更为强大
当然,这个只是ChatGPT在八爪鱼采集器中的一个场景,小八也正在探索把ChatGPT功能集成进八爪鱼采集器来辅助大家做好正则表达式,xpath等功能。
文末点赞让PM们看看大家对新功能期待程度,点赞越多,上线越快哦~




