xpath案例
数据字段缺失或错位
讲解当同一字段在不同页面位置不同时,如何通过设置备用位置 XPath 和修改字段 XPath 解决数据字段缺失或错位问题。
我们在提取一批相似网址时,页面中的字段一般是在同一位置,通过同一条定位XPath可以将其全部匹配到。但是存在这样一种情况,同一字段在不同页面的位置略有不同。这种情况会导致数据字段缺失或者错位的情况,这个时候可以通过修改字段的xpath进行解决。
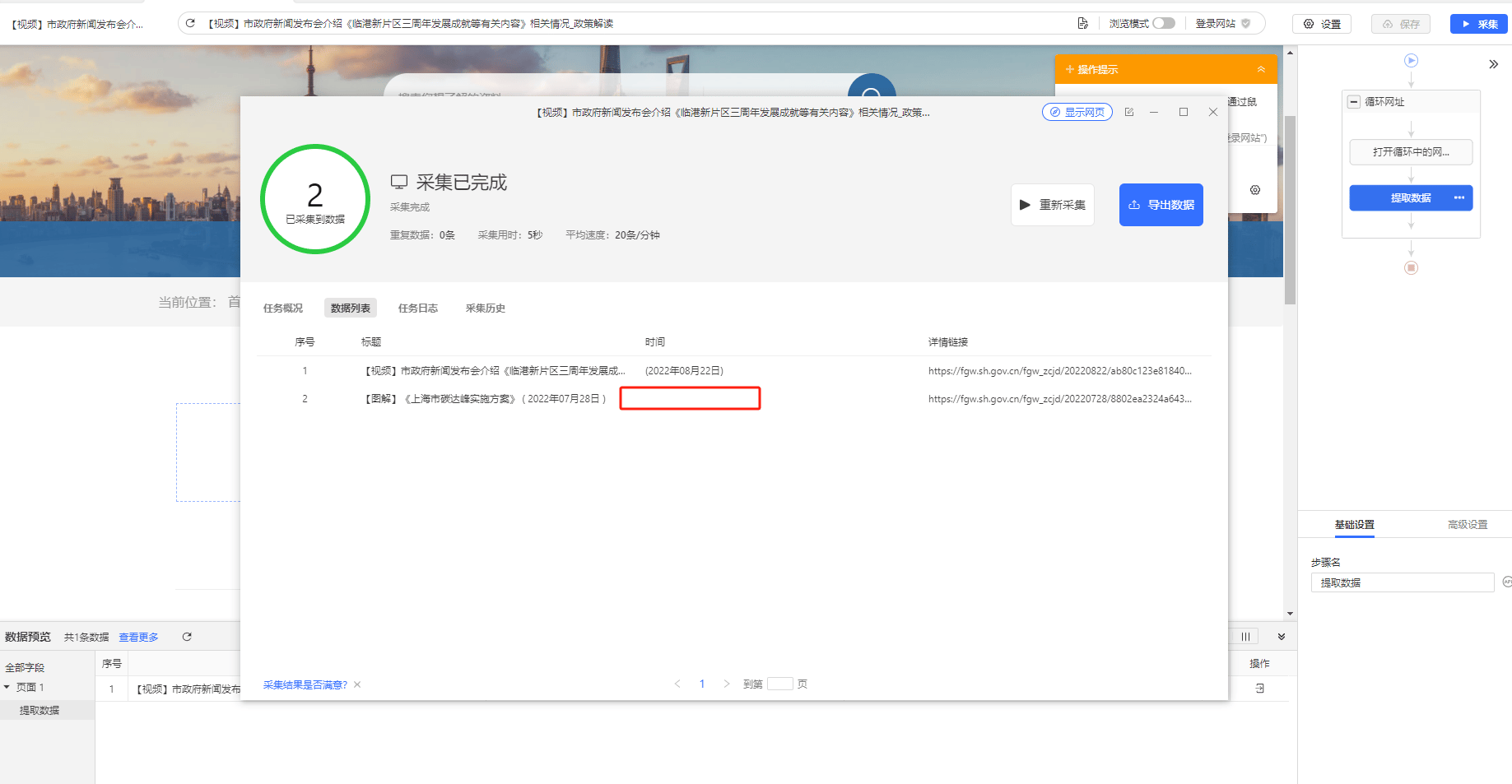
数据字段缺失:采集的某个字段,在A页可以正常采集,在B页采集为空。
示例网站:
https://fgw.sh.gov.cn/fgw_zcjd/20220822/ab80c123e81840c688ade0caa2f21a11.html
https://fgw.sh.gov.cn/fgw_zcjd/20220728/8802ea2324a643cbbfee5fc3b87dfad3.html
Step1:按照需求,采集数据。这里我们采集这2个详情页文章的标题、时间、正文链接
Step2:启动采集看一下,第2个详情页的【时间】字段并未采集到。这是因为第2个详情页的网页结构和第1个不同,第1个详情页的【时间】定位XPath,不适用第2个详情页了。